Linux/UNIX进程控制(1)
发布时间:2014-09-05 17:41:06作者:知识屋
进程控制(1)
进程标识符
每个进程都有肺腑的整形表示唯一的进程ID。按一个进程终止后,其进程ID就可以再次使用了。如下是几个典型进程的ID及其类型和功能。
ID 进程名 中文名 类型 作用
0 swapper 交换进程 系统进程 它是内核一部分,不执行磁盘上的程序,是调度进程。
1 init init进程 用户进程 永远不会终止,启动系统,读取系统初始化的文件。
2 pagedaemon页精灵进程 系统进程 虚存系统的请页操作
除了进程ID,每个进程还有一些其他的标识符。下列函数返回这些标识符:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void); //返回值:调用进程的进程ID
pid_t getppid(void); //返回值:调用进程的父进程ID
uid_t getuid(void); //返回值:调用进程的实际用户ID
uid_t geteuid(void); //返回值:调用进程的有效用户ID
gid_t getgid(void); //返回值:调用进程的实际组ID
gid_t getegid(void); //返回值:调用进程的有效组ID
fork函数
#include <unistd.h>
pid_t fork(void);
一个现有进程可以调用fork创建一个新进程。
返回值:子进程中返回0,父进程中返回子进程ID,出错返回-1。如下
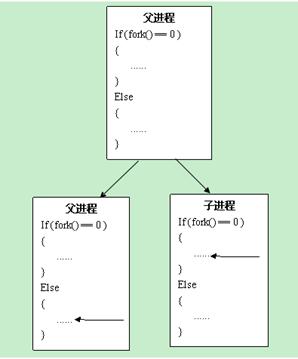
子进程是父进程的副本。例如:子进程获得父进程数据空间、堆和栈的副本。父子进程不共享这些存储空间部分。父子进程共享正文段。
由于fork之后经常归属exec,所以现在很多实现并不执行一个父进程数据段、栈和堆的完全复制。作为你替代,使用了写时复制(Copy-On-Write)技术。这些区域由父子进程共享,而且内核将他们的访问权限改变为只读的。如果父子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本。
下面的程序演示了fork函数,从中可以看出子进程对变量所作的改变并不去影响父进程中该变量的值。
#include <unistd.h>#include <stdio.h> int glob = 6; /* externalvariable in initialized data */char buf[] = "a write to stdout/n"; intmain(void){ int var; /* automatic variable on the stack */ pid_t pid; var = 88; if (write(STDOUT_FILENO, buf, sizeof(buf)-1) != sizeof(buf)-1) perror("write error"); printf("before fork/n"); /* we don't flush stdout */ if ((pid = fork()) < 0) { perror("fork error"); }else if (pid == 0) { /* child */ glob++; /* modifyvariables */ var++; }else { sleep(2); /* parent*/ } printf("pid = %d, glob = %d, var = %d/n", getpid(), glob,var); exit(0);}执行及输出结果:
chen123@ubuntu:~/user/apue.2e$./a.out
awrite to stdout
beforefork
pid= 2755, glob = 7, var = 89
pid= 2754, glob = 6, var = 88
chen123@ubuntu:~/user/apue.2e$./a.out > temp.out
chen123@ubuntu:~/user/apue.2e$cat temp.out
awrite to stdout
beforefork
pid= 2758, glob = 7, var = 89
beforefork
pid= 2757, glob = 6, var = 88
一般来说fork之后父进程和子进程的执行顺序是不确定的,这取决于内核的调度算法。在上面的程序中,父进程是自己休眠2秒钟,以使子进程先执行。
程序中fork与I/O函数之间的关系:write是不带缓冲 的,因为在fork之前调用write,所以其数据只写到标准输出一次。标准I/O是缓冲的,如果标准输出到终端设备,则它是行缓冲,否则它是全缓冲。当以交互方式运行该程序时,只得到printf输出的行一次,因为标准输出到终端缓冲区由换行符冲洗。但将标准输出重定向到一个文件时,由于缓冲区是全缓冲,遇到换行符不输出,当调用fork时,其printf的数据仍然在缓冲区中,该数据将被复制到子进程中,该缓冲区也被复制到子进程中。于是父子进程的都有了带改行内容的标准I/O缓冲区,所以每个进程终止时,会冲洗其缓冲区中的数据,得到第一个printf输出两次。
文件共享
fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。父子进程的每个相同的打开描述符共享一个文件表项。假设一个进程有三个不同的打开文件,在从fork返回时,我们有如下所示结构:
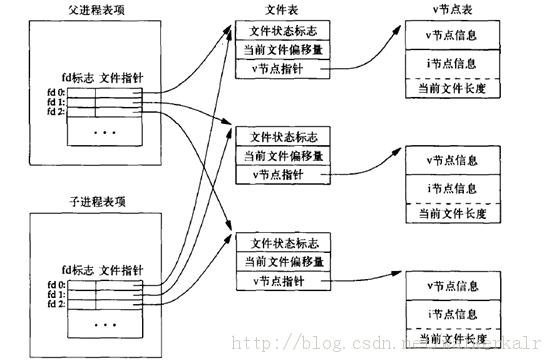
在fork之后处理的文件描述符有两种常见的情况:
1. 父进程等待子进程完成。在这种情况下,父进程无需对其描述符做任何处理。当子进程终止后,子进程对文件偏移量的修改已执行的更新。
2. 父子进程各自执行不同的程序段。这种情况下,在fork之后,父子进程各自关闭他们不需要使用的文件描述符,这样就不会干扰对方使用文件描述符。这种方法在网络服务进程中经常使用。
父子进程之间的区别:
1. fork的返回值
2. 进程ID不同
3. 具有不同的父进程ID
4. 子进程的tms_utime、tms_stime、tms_cutime及tms_ustime均被设置为0
5. 父进程设置的文件锁不会被子进程继承
6. 子进程的未处理闹钟被清除
7. 子进程的未处理信号集被设置为空集
fork有下面两种用法:
1. 一个父进程希望复制自己,使父子进程同时执行不用的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
2. 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因:
1. 系统中有太多的进程
2. 实际用户的进程数超过了限制
vfork函数
vfork函数的调用序列和返回值与fork相同,但两者的语义不同。
vfork用于创建一个新进程,而该新进程的目的是exec一个新程序。vfork与fork都创建一个子进程,但它不将父进程的地址空间复制到子进程中,因为子进程会立即调用exec,于是不会存访问该地址空间。相反,在子进程调用exec或exit之前,它在父进程的空间中运行,也就是说会更改父进程的数据段、栈和堆。vfork和fork另一区别在于:vfork保证子进程先运行,在它调用exec之后父进程才可能被调度运行。
下面是vfork的使用程序:
#include"unistd.h"#include"stdio.h" int glob = 6; /* external variable in initialized data*/ intmain(void){ int var; /* automatic variableon the stack */ pid_t pid; var = 88; printf("before vfork/n"); /* we don't flush stdio */ if ((pid = vfork()) < 0) { perror("vfork error"); } else if (pid == 0) { /* child */ glob++; /* modify parent's variables*/ var++; _exit(0); /* child terminates */ } /* * Parent continues here. */ printf("pid = %d, glob = %d, var =%d/n", getpid(), glob, var); exit(0);} 执行及输出结果如下所示:
chen123@ubuntu:~/user/apue.2e$./a.out
before vfork
pid = 2984, glob= 7, var = 89
可见子进程直接改变了父进程的变量值,因为子进程在父进程的地址空间中运行。
这里子进程调用_exit是因为_exit并不执行标准I/O缓冲的冲洗操作。如果调用exit,该程序结果不确定,依赖于标准I/O库的实现。因为exit有可能关闭标准I/O流,那么会使父进程不产生任何输出。
exit函数
进程有5中正常终止方式,3中异常终止方式。(见上一篇文章)。
对于任意一种终止情形,我们都希望终止进程能够统治父进程它是如何终止的。对于三个终止函数(exit、_exit和_Exit),实现这一点的方法是,将其退出状态作为参数传送给函数。在异常终止情况下,内核产生一个指示其异常终止原因的终止状态。在任意一种情况下,该终止状态的父进程都能使用wait或waitpid函数取得其终止状态。
在调用_exit时,内核将进程的退出状态转换成终止状态。
对于父进程已经终止的所有进程,他们的父进程都改变为init进程。我们称这些进程有Init领养。一个init的子进程(包括领养进程)终止时,init会调用一个wait函数取得其终止状态。
对于一个已经终止、但其父进程尚未对其进行善后处理(获取终止子进程的有关信息,释放它仍占有的资源)的进程被称为僵尸进程。子进程终止时,虽然不在运行,但它仍然存在与系统中,进程表中代表子进程的表项不会立刻被释放,因为它的退出码还需要保存在进程表项中以备父进程今后的wait调用使用,也就是说终止子进程与父进程之间的关联还会保持,直到父进程也正常的终止或父进程调用wait才告结束。
wait和waitpid函数
当一个进程正常或异常终止时,内核就向其父进程发送一个SIGCHLD信号。因为子进程终止是一个异步事件,所以发生这种信号也是内核向父进程发的异步通知。父进程可以选择忽略该信号,或者提供一个该信号发生时即被调用执行的函数。对于这种信号的系统默认动作是忽略它。现在需要知道的是调用wait或waitpid的进程可能会发生什么情况:
1.如果其所有子进程都还在运行,则阻塞
2.如果一个子进程已终止,正等待父进程获取其终止状态,则取得该子进程的终止状态立即返回。
3.如果它没有任何子进程,则立即出错返回。
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
pid_twaitpid(pid_t pid, int *status, int options);
如果进程由于接收到SIGCHLD而调用wait,则可期望wait会立即返回。但如果在任意时刻调用wait,则进程可能阻塞。
在一个子进程 终止前,wait使其调用者阻塞,而waitpid有一个选项,可使调用者不阻塞。
这两个函数的参数statloc是一个整形指针。如果statloc不是一个空指针,则终止进程的终止状态就存放在它所指的单元内。如果不关心终止状态,则可将该参数设为空指针。
可用以下宏来检查wait和waitpid所返回的终止状态:
WIFEXITED(status) 若为正常终止子进程返回的状态,则为真。
WEXITSTATUS(status) 若WIFEXITED非零,返回子进程退出码。
WIFSIGNAKED(status) 若为子进程异常终止返回状态(收到一个未捕捉的信号),则为真
WTERMSIG(status) 若WIFSIGNAKED非零,则返回一个信号编号
WIFSTOPPED 若为子进程意外终止,则为真
WSTOPSIG 若WIFSTOPPED非零,返回一个信号编号
waiptpid提供了wait没有提供的三个功能:
1. waitpid可等待一个特定的进程
2. waitpid提供了一个wait的非阻塞版本
3. waitpid支持作业控制
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












