《linux性能及调优指南》3.4硬盘瓶颈
发布时间:2014-09-05 13:30:57作者:知识屋
The disk subsystem is often the most important aspect of server performance and is usually the most common bottleneck.
However, problems can be hidden by other factors, such as lack of memory.
Applications are considered to be I/O-bound when CPU cycles are wasted simply waiting for I/O tasks to finish.
磁盘子系统是服务器性能最重要的方面,通常它也是最常见的瓶颈;
然而,它的问题通常隐藏在其它因素之下,如缺少内存;
当CPU周期都浪费在等待I/O任务完成时,这样的应用程序被认为是I/O密集型;
The most common disk bottleneck is having too few disks.
Most disk configurations are based on capacity requirements, not performance.
The least expensive solution is to purchase the smallest number of the largest capacity disks possible.
However, this places more user data on each disk,
causing greater I/O rates to the physical disk and allowing disk bottlenecks to occur.
最常见的磁盘瓶颈是硬盘太小;
大多数的磁盘配置是基于容量需求,而不是性能;
最便宜的解决方案可能是少量的大容量磁盘;
The second most common problem is having too many logical disks on the same array.
This increases seek time and significantly lowers performance.
The disk subsystem is discussed in 4.6, “Tuning the disk subsystem” on page 112.
第二个常见的问题是在同一个陈列中有过多的逻辑磁盘,
这会增加寻道时间而显著降低性能;
3.4.1 Finding disk bottlenecks
寻找磁盘瓶颈
A server exhibiting the following symptoms might be suffering from a disk bottleneck (or a hidden memory problem):
如果服务器出现了下列现象就有可能是遇到了磁盘瓶颈(或隐含的内存问题):
. Slow disks will result in 缓慢的磁盘会导致:
– Memory buffers filling with write data (or waiting for read data), which will delay all
requests because free memory buffers are unavailable for write requests (or the
response is waiting for read data in the disk queue).
内存buffer将会被写数据填充(或等待读数据),这会导致所有的响应变慢,
因为对于写请求来说,没有可用的空间内存buffer(或这个响应在等待从磁盘队列中读数据)。
– Insufficient memory, as in the case of not enough memory buffers for network requests,
will cause synchronous disk I/O.
内存不足,在没有足够的内存缓冲用于网络请求的情况下,将导致磁盘I/O 同步;
. Disk utilization, controller utilization, or both will typically be very high.
磁盘利用率,控制器利用率,或者这两者都很有可能;
. Most LAN transfers will happen only after disk I/O has completed, causing very long
response times and low network utilization.
大多数的的LAN传输都会在磁盘I/O完成后会发生,会造成非常长的响应时间和很低的网络选用率;
. Disk I/O can take a relatively long time and disk queues will become full, so the CPUs will
be idle or have low utilization because they wait long periods of time before processing the
next request.
磁盘I/O会消耗很长的时间并导致磁盘队列变满,因此CPU将会变得很闲或很低的利用率,
因为它们在处理下个响应之前,要等待很长的时间;
The disk subsystem is perhaps the most challenging subsystem to properly configure.
Besides looking at raw disk interface speed and disk capacity, it is also important to understand the workload.
Is disk access random or sequential? Is there large I/O or small I/O?
Answering these questions provides the necessary information to make sure the disk subsystem is adequately tuned.
磁盘子系统可能是实现合适配置的最有挑战的子系统;
除了要关注原始磁盘接口速度和硬盘容量外,工作负载也同样重要;
磁盘访问是随机的还是序列的?是重I/O,还是轻I/O的?
只有回答了这些问题后才能提供必要的信息来调整磁盘子系统;
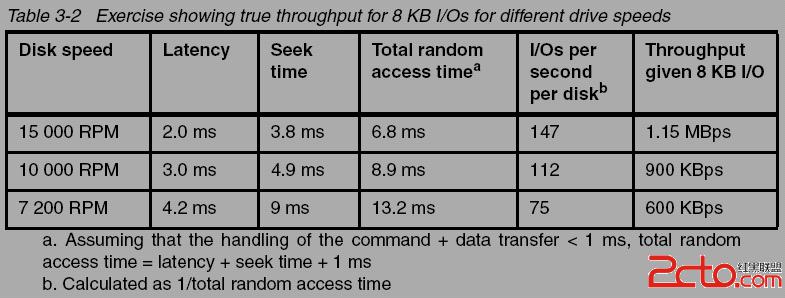
Disk manufacturers tend to showcase the upper limits of their drive technology’s throughput.
However, taking the time to understand the throughput of your workload will help you
understand what true expectations to have of your underlying disk subsystem.
磁盘制造商倾向于炫耀他们驱动技术的吞吐量的上限,
然而,理解你工作负载的吞吐量将有助于理解你对磁盘子系统的真正期望;
Random read/write workloads usually require several disks to scale.
The bus bandwidths of SCSI or Fibre Channel are of lesser concern.
Larger databases with random access workload will benefit from having more disks.
Larger SMP servers will scale better with more disks.
Given the I/O profile of 70% reads and 30% writes of the average commercial workload,
a RAID-10 implementation will perform 50% to 60% better than a RAID-5.
随机读/写工作负载通常请求多个磁盘扩展;
SCSI的bus的带宽或Fibre通常不怎么关注;
随机访问方式的大数据库在多个磁盘情况下很有好处;
大型SMP服务器在扩展上要好于多磁盘;
假如平均工作负载 是70%的读和30%的写,则RAID-10要比RAID-5效率高50%~60%;
Sequential workloads tend to stress the bus bandwidth of disk subsystems.
Pay special attention to the number of SCSI buses and Fibre Channel controllers when maximum throughput is desired.
Given the same number of drives in an array, RAID-10, RAID-0,
and RAID-5 all have similar streaming read and write throughput.
序列工作负载对bus带宽和磁盘子系统有很大的压力;
假如在陈列中有相同数量的磁盘,RAID-10, RAID-0, RAID-5有相同的流读写吞吐量;
There are two ways to approach disk bottleneck analysis:
real-time monitoring and tracing.
有两种方法来对磁盘瓶颈进行分析:
实时监测和跟踪;
. Real-time monitoring must be done while the problem is occurring. This might not be
practical in cases where system workload is dynamic and the problem is not repeatable.
However, if the problem is repeatable, this method is flexible because of the ability to add
objects and counters as the problem becomes clear.
实时监测必须在问题出现时做,这在系统负载是动态的且问题不能重现时很难操作,
然而,如果问题可以重现,这个方法就很有用了;
. Tracing is the collecting of performance data over time to diagnose a problem. This is a
good way to perform remote performance analysis. Some of the drawbacks include the
potential for having to analyze large files when performance problems are not repeatable,
and the potential for not having all key objects and parameters in the trace and having to
wait for the next time the problem occurs for the additional data.
跟踪是通过长时间收集性能数据来诊断问题,对于远程性能分析来说,这是一个很好的方法;
但这个方法也有一些缺点,分析大文件时,性能问题不可重复;
未对重要对象和参数进行跟踪等;
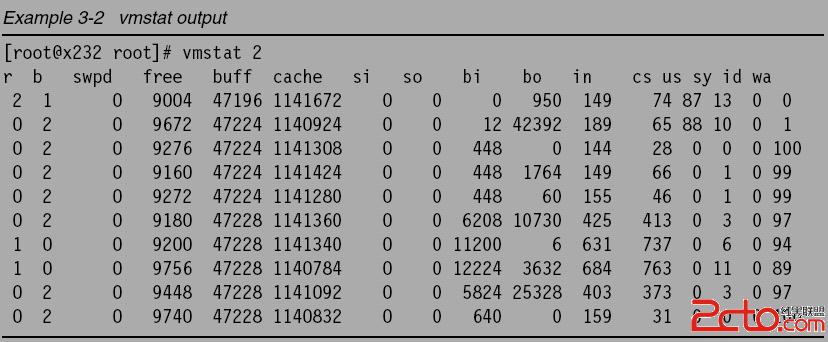
vmstat command
One way to track disk usage on a Linux system is by using the vmstat tool. The important
columns in vmstat with respect to I/O are the bi and bo fields. These fields monitor the
movement of blocks in and out of the disk subsystem. Having a baseline is key to being able
to identify any changes over time.
Linux系统的硬盘跟踪工具可以使用vmstat,
它是最重要的列是bi和bo, 它们监测了有磁盘子系统的块的输入和输出的移动,
有一个基准线来标识改变很重要;
iostat command
Performance problems can be encountered when too many files are opened, read and written
to, then closed repeatedly. This could become apparent as seek times (the time it takes to
move to the exact track where the data is stored) start to increase. Using the iostat tool, you
can monitor the I/O device loading in real time. Different options enable you to drill down even
deeper to gather the necessary data.
iostats可以用于监测实时的I/O设备负载,不同的选项可做进一步的分析;
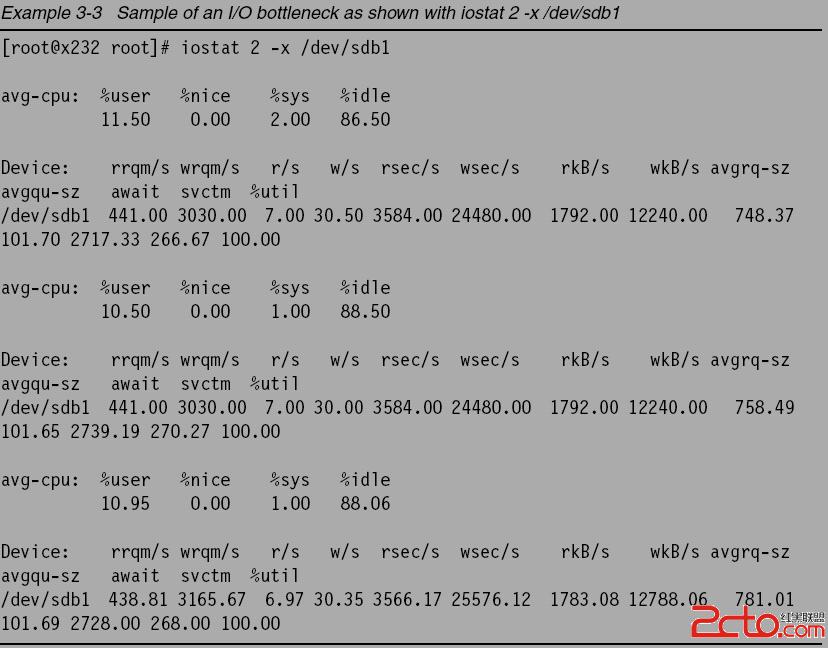
Example 3-3 shows a potential I/O bottleneck on the device /dev/sdb1. This output shows
average wait times (await) of about 2.7 seconds and service times (svctm) of 270 ms.
For a more detailed explanation of the fields, see the man page for iostat(1).
Changes made to the elevator algorithm as described in 4.6.2, “I/O elevator tuning and
selection” on page 115 will be seen in avgrq-sz (average size of request) and avgqu-sz
(average queue length). As the latencies are lowered by manipulating the elevator settings,
avgrq-sz will decrease. You can also monitor the rrqm/s and wrqm/s to see the effect on the
number of merged reads and writes that the disk can manage.
更多的细节可见iostat的man页面;
3.4.2 Performance tuning options
性能调整选项
After verifying that the disk subsystem is a system bottleneck, several solutions are possible.
当确认磁盘子系统是系统瓶颈时,有多个解决办法可用;
These solutions include the following:
. If the workload is of a sequential nature and it is stressing the controller bandwidth, the
solution is to add a faster disk controller. However, if the workload is more random in
nature, then the bottleneck is likely to involve the disk drives, and adding more drives will
improve performance.
如果工作负载是序列式的且控制器的带宽压力很大时,解决办法是添加更快速的磁盘控制器;
如果工作负载是随机式的时,瓶颈可能是硬盘驱动,增加驱动可以改善性能;
. Add more disk drives in a RAID environment. This spreads the data across multiple
physical disks and improves performance for both reads and writes. This will increase the
number of I/Os per second. Also, use hardware RAID instead of the software
implementation provided by Linux. If hardware RAID is being used, the RAID level is
hidden from the OS.
在RAID环境中添加更多的磁盘驱动,这能使数据跨越多个物理磁盘并改善读写性能;
同样,使用硬件RAID替代软件RAID也有效果;
. Consider using Linux logical volumes with striping instead of large single disks or logical
volumes without striping.
考虑使用Linux条带方式的逻辑卷;
. Offload processing to another system in the network (users, applications, or services).
卸载进程到网络的另一个系统;
. Add more RAM. Adding memory increases system memory disk cache, which in effect
improves disk response times.
增加更多的RAM,添加内存增加了系统的内存磁盘cache, 可以改善磁盘的响应时间;
(免责声明:文章内容如涉及作品内容、版权和其它问题,请及时与我们联系,我们将在第一时间删除内容,文章内容仅供参考)
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












