浅谈linux性能调优之三:分区格式化之前的考虑
发布时间:2014-09-05 14:13:54作者:知识屋
浅谈linux性能调优之三:分区格式化之前的考虑
有这么一种特殊情况可能在生产环境下发生:系统的某个ext3文件分区,当用户往此分区上写文件时,提示磁盘空间已满,但用df -h命令查 看时发现此分区磁盘使用量是60%,请分析出现这种情况是由什么导致的,答案是inode已经耗尽!
为什么呢 ?
给出一个ext*文件系统的结构图
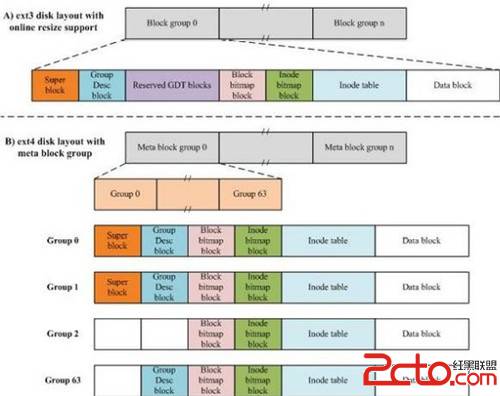
在Linux中进行格式化必须考虑Block与inode,Block还好理解,它是磁盘可以记录的最小单位,是由数个扇区组成,所以大小通常为n*512Bytes,例如4K。 那么inode是什么呢 ? Block是记录文件内容的区域,inode则是记录该文件的属性及其放置在哪个Block之内的信息。每个inode分别记录一个档案的属性与这个档案分布在哪些datablock上(也就是我们说的指针,有的地方也叫索引编号)。
具体如下:
● inode 编号 ● 用来识别文件类型,以及用于 stat C 函数的模式信息 ● 文件的链接数目 ● 属主的 UID ● 最近一次访问的时间 ● 属主的组 ID(GID) ● 文件的大小 ● 文件所使用的磁盘块的实际数目 ● 最近一次修改的时间 ● 最近一次更改的时间
小结:inode两个功能:记录档案属性和指针所以,每个文件都会占用一个inode。当Linux系统要查找某个文件时,它会先搜索inode table找到这个文件的属性及数据存放地点,然后再查找数据存放的Block进而将数据取出。一个分区被格式化为一个文件系统之后,基本上它一定会有inode table与数据区域两大块,一个用来记录文件的属性信息与该文件存放的Block块,一个用来记录文件的内容。
一个逻辑上的概念: 一个block对应一个inode吗? 答案是否定的,一个大文件虽然占用很多的block,但是只使用了一个inode
测试1: 我添加磁盘并划分分区,/dev/sdb5,6,7各100M 并指定block大小分别是1k,2k,4k格式化时得到结构inode数量都是28000多 (-b)
结论:inode和block没有直接关系!网上有一种说说“block越大,inode越小的说法”显然错误
测试2: 我使用-i 选项格式化 (-i bytes-per-inode
Specify the bytes/inode ratio. mke2fs creates an inode for every bytes-per-inode bytes of space on the disk. The larger the bytes-per-inode ratio, the fewer inodes will be created. This value generally shouldn’t be smaller than the blocksize of the filesystem, since in that case more inodes would be made than can ever be used. Be warned that it is not possible to expand the number of inodes on a filesystem after it is created, so be careful deciding the correct value for this parameter.
)
结论:指定i越小,inode越大,注意这还是和block没关系!只是用户自定义inode数量而已!
注意:一个文件占用一个inode,但是至少占用一个block,不管block数量有多大,1K,2K,4K,文件小于blocksize时,占用一个block,此block的剩余空间别的文件无法使用!若文件大于blocksize时,直接使用多个block
于是,就有了最终结论:(当然这里不是细算!)
分区总量/block大小 >= inode数 ------ > 能创建的文件数量的最大值 = inode数
分区总量/block大小 < inode数 --------> 能创建的文件数量的最大值 = 分区总量/block大小的数量个文件
若分区是提供给给大文件应用,一般不做考虑
相反,若分区是提供给小文件应用,则一定要自己计算并格式化,以免inode耗尽,磁盘分区却未使用完
*******************************************************************************
测试1数据:
[root@desktop132 ~]# mkfs.ext3 -b 1024 /dev/sdb5
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
28112 inodes, 112392 blocks
5619 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
[root@desktop132 ~]# mkfs.ext3 -b 2048 /dev/sdb6
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=2048 (log=1)
Fragment size=2048 (log=1)
Stride=0 blocks, Stripe width=0 blocks
28160 inodes, 56210 blocks
2810 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=57671680
4 block groups
16384 blocks per group, 16384 fragments per group
7040 inodes per group
Superblock backups stored on blocks:
16384, 49152
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
[root@desktop132 ~]# mkfs.ext3 -b 4096 /dev/sdb7
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
28128 inodes, 28105 blocks
1405 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=29360128
1 block group
32768 blocks per group, 32768 fragments per group
28128 inodes per group
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done
*******************************************************************************
*******************************************************************************
测试2数据:
[root@desktop132 ~]# mkfs.ext3 -i 1024 /dev/sdb5
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
112448 inodes, 112392 blocks
5619 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
8032 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 31 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@desktop132 ~]# mkfs.ext3 -i 2048 /dev/sdb6
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
56224 inodes, 112420 blocks
5621 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
4016 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 35 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@desktop132 ~]# mkfs.ext3 -i 4096 /dev/sdb7
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
28112 inodes, 112420 blocks
5621 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
14 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 37 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
*******************************************************************************
(免责声明:文章内容如涉及作品内容、版权和其它问题,请及时与我们联系,我们将在第一时间删除内容,文章内容仅供参考)
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












