统计特定文件中的词频
发布时间:2014-09-05 14:17:20作者:知识屋
统计特定文件中的词频
查找文件中使用的单词的频率是一件很有意思的事情,下面,我们利用 关联数组,awk,sed,grep 等不同的方式来解决问题。
首先,我们需要一个测试用的文本,保存名为 word.txt
内容如下:
[python]
Word used
this counting
this
接下来需要编写Shell脚本程序,如下所示:
[python]
#!/bin/bash
#Name: word_freq.sh
#Description: Find out frequency of words in a file
if [ $# -ne 1 ];
then
echo "Usage: $0 filename";
exit -1
fi
filename=$1
egrep -o "/b[[:alpha:]]+/b" $filename | /
awk '{ count[$0]++ } END{ printf("%-14s%s/n","Word","Count") ; /
for(ind in count) { printf("%-14s%d/n",ind,count[ind]); } }'
工作原理介绍:
1.egrep -o "/b[[:alpha:]]+/b" $filename 用来只输出单词,用 -o 选项打印出由换行符分割的匹配字符序列,这样我们就可以在每行中列出一个单词
2./b 是单词边界标记符。[:alpha:] 是表示字母的字符类
3.awk命令用来避免对每一个单词进行迭代
下面给出运行的截图:
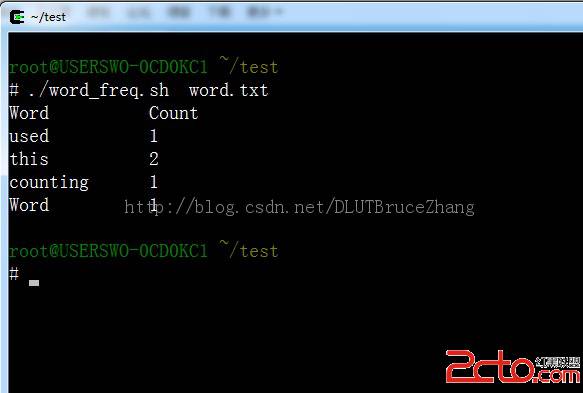
(免责声明:文章内容如涉及作品内容、版权和其它问题,请及时与我们联系,我们将在第一时间删除内容,文章内容仅供参考)
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












