Sed和AWK入门教程之AWK篇
发布时间:2014-09-05 14:17:49作者:知识屋
Sed和AWK入门教程之AWK篇
AWK是一门专门用于文本处理的编程语言.是的,它是编程语言,它的目的仅有文本处理,所以你不能用它写系统软件,或者做科学计算(当然,它也能做数学计算),它只能用于文本处理.与sed不同,AWK具有编程语言的特性,有内置函数,有逻辑语句,有输入输出语句,其实它看起来很像C语言,只不过所有功能集中于文本处理.
与Sed不同,AWK最强大的功能在于处理结构化的文本,也就是说文本有一定的组织结构的.
命令格式
awk [-F value] [-v var=value] 'program text' [files....]
awk [-F value] [-v var=value] -f program-file [files....]
例如:
[plain]
[alex@alexon:~]$awk '{print}' persons.txt
1011, Alex Perkins, Product, Software Developer
3923, Jimmey Mills, Operation, COO
23934, Kevin Kim, Management, CEO
2321, Chris Paul, UI, Designer
又见cat,呵呵. 更有意义一点的:
[plain]
[alex@alexon:~]$awk -F , -v OFS=: '{print $1, $2, $3, $4}' persons.txt
1011: Alex Perkins: Product: Software Developer
3923: Jimmey Mills: Operation: COO
23934: Kevin Kim: Management: CEO
2321: Chris Paul: UI: Designer
awk能识别文本的结构,还能格式化输出.
程序的格式
也就是'program text'或者program file中的内容:
BEGIN {actions} /pattern/ {actions} END {actions}
BEGIN是处理文件之前执行的. 中间的叫Body loop.后面的END是处理完结束后执行.
可以用/来实现分行输入:
BEGIN {action} /
/pattern {action} /
END {action}
如果写在文件中,则可以像写C语言那样写
program-file.awk:
BEGIN {
actions;
}
/pattern/ {
actions;
}
END {
actions;
}
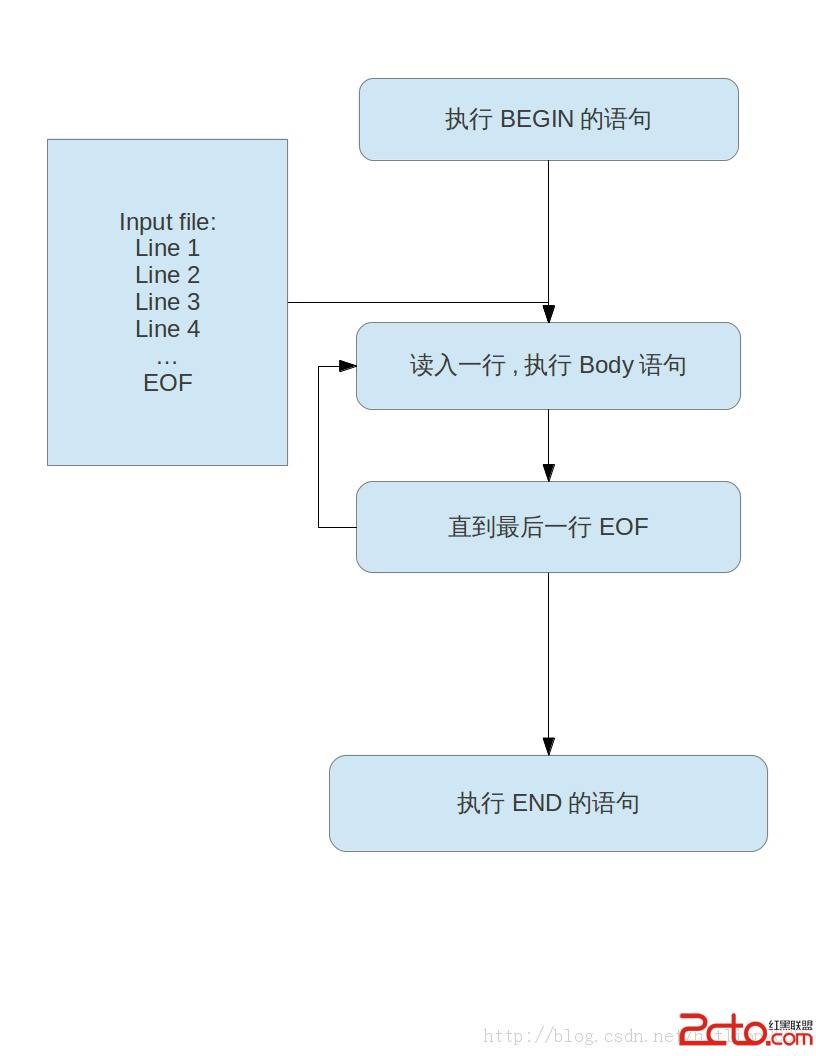
AWK的执行方式,先执行BEGIN段内的内容,然后对文件的每一行,执行body,所有行都处理完后,执行END段.也就是说BEGIN和END都只执行一次,而Body loop要执行很多次,视行数和模式匹配而定,因为要执行多次,所以它叫Body loop.
内置变量
AWK会假定输入的文本是一个结构化文本,也即是一个表格形式的,每一行是一个记录(Record),每一列是一个域(Field).AWK读入时会以结构化方式对文本进行处理,这时就用到了一些内置变量:
FS -- Field Separator 域的分隔符,默认的是以空白符分隔
RS -- Record Separator 记录的分隔符,默认是以换行符来分隔
FILENAME -- current filename
NF -- Number of Feilds in current record
NR -- Number of Record 输入的记录数,相当于行号一样,多个文件时会接着递增.
FNR -- File Number of Record 输入的当前记录数,每个文件单独计算
$0 -- the whole record 当前整个记录
$n -- the nth field of the current record 当前记录和第n个域
利用这些内置变量,AWK读入文本后就可以对文本进行处理,以达到分解结构化文本的目的:把输入变成一个Table形式的结构化信息.
对就的,输出的时候也有对应的变量来控制输出的格式:
OFS -- Ouput Field Separator 输出时的域分隔符
ORS -- Output Record Separator 输出时的记录分隔符
语句(actions)
print语句
以字串形式输出,后面的每个变量都当成是字串.当以逗号分隔时,就用OFS来分隔域,如果以空格分隔时,就以空格来作为OFS:
[plain]
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1,$2,$3,$4}' persons.txt
1011; Alex Perkins; Product; Software Developer
3923; Jimmey Mills; Operation; COO
23934; Kevin Kim; Management; CEO
2321; Chris Paul; UI; Designer
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1 $2 $3 $4}' persons.txt
1011 Alex Perkins Product Software Developer
3923 Jimmey Mills Operation COO
23934 Kevin Kim Management CEO
2321 Chris Paul UI Designer
print不跟参数时,输出当前的记录.
printf语句
可以进行与C语言十分类似的格式化输出.
[plain]
[alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {printf "%d: ", NR; print $1,$2,$3,$4}' persons.txt
1: 1011; Alex Perkins; Product; Software Developer
2: 3923; Jimmey Mills; Operation; COO
3: 23934; Kevin Kim; Management; CEO
4: 2321; Chris Paul; UI; Designer
程序语言
与C语言十分类似.有运算符,有内置函数,有变量,可以实现十分强大的功能,这部分通常用不到,也不是一篇文章能讲的清的,可以参考awk的man文档或者书籍.推荐<Sed & Awk><Sed and Awk 101 Hacks>
正则表达式
元字符有: ^ $ . [ ] | ( ) * + ?
AWK中的与标准的正则表达式一样:
位置符:
^ --- 行首
$ ----行尾
. ----任意非换行符'/n'符
/b ---- 一个单词结尾,单词定义为一连串的字母或数字,可以单独放在一端,也可放二端.
限量符
* --- 0或1个或多个
+ --- 1个或多个
? --- 0或1
{m} --- 出现m次
{m,n} --- 出现m次到n次,如{1,5}表示出现1次到5次不等(1,2,3,4,5次)
转义符
/ --- 可以转义特殊字符
字符集
[] ---其内的任意字符
[^] --- 匹配任何不在此字符集中的字符
操作符
| ---- 或操作,abc/|123匹配123或者abc
(...) ----组合,形成一个组,主要用于索引
/n ---- 前面第n个组合, //(123/)/1/ 则匹配123123
(免责声明:文章内容如涉及作品内容、版权和其它问题,请及时与我们联系,我们将在第一时间删除内容,文章内容仅供参考)
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












