MD模块之处理读写过程分析-2
发布时间:2014-09-05 17:07:27作者:知识屋
这一节讲述raid5模块中处理读写流程。这个过程很复杂,最关键的函数就是handle_stripe,处理一次读或写都会多次调用这个函数才能完成。当然,这个函数也是raid5模块的一个核心函数,他还负责同步,重建,以及扩展的实现。在分析之前,我们需要准备一些预备知识:
一、条带:我们知道,raid5是以条带为基本单位来存取数据的。如下图所示:
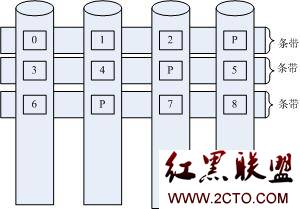
raid5还有其它中数据分布方式,这里只列出一种。图中的block0,block1,block2等这些数据块在逻辑上是连续的。
值得注意的是,MD中raid5处理数据的最小单位是一个由大小4KB组成的小条带,即一个页大小,并不是一次处理一个block大小的条带。以后出现的条带均指的是这个由4KB组成的小条带。这个数据结构如下:
struct stripe_head {
struct hlist_node hash;
struct list_head lru; /* inactive_list or handle_list */
struct raid5_private_data *raid_conf;
sector_t sector; /* sector of this row */
int pd_idx; /* parity disk index */
unsigned long state; /* state flags */
atomic_t count; /* nr of active thread/requests */
spinlock_t lock;
int bm_seq; /* sequence number for bitmap flushes */
int disks; /* disks in stripe */
struct r5dev {
struct bio req;
struct bio_vec vec;
struct page *page;
struct bio *toread, *towrite, *written;
sector_t sector; /* sector of this page */
unsigned long flags;
} dev[1]; /* allocated with extra space depending of RAID geometry */
};
其中主要字段的意义:
hash:条带在缓冲中hash表项。
lru:条带所处在那个链表中
sector:条带所处的扇区号,这个扇区号是从单个磁盘的起始地址算起的一个偏移量。
state:条带的状态位
r5dev:条带中描述每个设备的缓冲区,这个结构体是处理io的最小单位,命令经计分解算之后,会被加入相应条带中相应r5dev中的链表中,也就是结构体中toread,towrite链表中(通过bio->bi_next连接起来)。在这个结构体中字段req代表请求bio,vec代表bio中的段,sector的意义说该r5dev在阵列中的逻辑扇区号。flags字段代表设备缓冲区的状态。这些状态可以在raid5.h中找到.
二、条带中设备缓冲区的状态
前面所说的r5dev中的flags字段,其中两位很重要,即
#define R5_UPTODATE 0 /* page contains current data */
#define R5_LOCKED 1 /* IO has been submitted on "req" */
这两位可以代表缓冲区的4中状态,依次是:empty (!R5_UPTODATE !R5_LOCKED )表明缓冲区为空
want (R5_LOCKED !R5_UPTODATE )表明缓冲区要请求数据
clean (!R5_LOCKED R5_UPTODATE )表明缓冲区中的数据与磁盘上的一致。
dirty(R5_LOCKED R5_UPTODATE )表明缓冲区有有新的数据要写入磁盘中。
在数据的读写过程中,缓冲区的状态会伴随着改变,这些将会在以后中体现。
接下来我们看看make_request函数,它的功能是实现了请求的重新分发,确定了bio会加入到那个条带的那个设备读写链表中。具体过程如下:
(先略过代码段
if (rw == READ &&mddev->reshape_position ==
MaxSector &&chunk_aligned_read(q,bi))
return 0;
这段意义以后在说)
a、调用md_write_start函数,该函数判断是否需要更新元数据。由于一些raid算法带有冗余特性,比如raid1,raid5,那么开始写数据时,就要进行更新元数据,这防止写数据不成功导致数据不正确,在阵列再次启动时就会发起同步操作。写完之后还要更新元数据。MD是通过in_sync字段来判断的。如果in_sync=1,说明阵列是同步的。这时就有一个疑问,不能来一次写请求就更新二次元数据吧?确实,md为了防止这样事情发生,引入了一个定时器,即200ms内没有连续的写请求发过来就更新元数据。这个功能通过safemode值的重载来完成。
b、计算bio的起始逻辑扇区号logical_sector和最后扇区号last_sector,这里的logical_sector计算方式为logical_sector = bi->bi_sector & ~((sector_t)STRIPE_SECTORS-1);其意义是将bio的起始扇区号对齐到条带,即如果bi_sector=6的话,那么logical_sector=0.
c、进入循环,对于每个logical_sector,首先判断其是否正在扩容(conf->expand_progress!=MaxSector)目的是支持在线扩容,即阵列扩容的时候可以访问阵列.如果正在扩容,还要判断logical_sector是否在正在扩容的区间内,如果是的话则休眠,否则根据情况进行处理。这里不做过多描述,在扩容的时候在说。
d、通过函数raid5_compute_sector计算logical_sector所在磁盘相对于开始位置的偏移量new_sector, 同时这个函数还确定了logical_sector所在条带的设备号dd_index和校验盘号pd_index.
e、根据第三步计算的new_sector的值来获取条带,函数get_active_stripe首先判断该条带是否在条带缓冲区中,如果在的话直接返回。否则试图从inactive_list中寻找不活动的条带,如果找到则调用init_stripe来初始化,否则休眠。这个函数的第三个参数代表是否通过非阻塞方式来获取活动条带。对于读写,我们发现第3个参数为(bi->bi_rw&RWA_MASK),即处理读写时使用的阻塞的方式来获取条带,即保证了在读写的时一定要能获取到条带。如果找到了符合条件的条带,如果在阵列在扩展中会判断是否需要重试这个条带。因为在获取条带的过程中可能引起休眠,就会导致原来logical_sector>expand_prograss变成了logical_sector<expand_prograss,。如果还按之前计算的new_sector进行处理的话,那么会造成错误。所以这里要retry.
f、之后通过add_stripe_bio将这个bio插入到条带中,注意,bio会被插入到多个条带中,当每个条带均处理完成时,这个bio也就处理完了,这个计数器是由bi_phys_segments来维护的。当bio插入到一个条带中bi_phys_segments++,当处理完一个条带bi_phys_segments--。这个函数还会判断要插入的bio是否覆盖整个r5dev,即是否为满写,这个判断在处理写请求(以rcw方式)时有用。
g、此时,我们已经把bio加入到了该加入的条带中,之后就要处理这个条带。这个功能由handle-stripe函数来完成。由于这个函数很复杂,我会在下一节中单独做分析。
h、handle_stripe函数结束之后,会release_stripe函数,这个函数的功能就是根据条带的状态将调到加入到不同的链表中以便之后继续使用。
下一节我会以一次简单的读写来分析handle_stripe函数。读比较简单,写过程较麻烦,涉及到了延迟写。
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












