linux后端诊断与调试技术
发布时间:2015-02-02 18:31:15作者:知识屋
下面出现的问题是工程师日常开发中真实写照。

诊断技术与调试解释
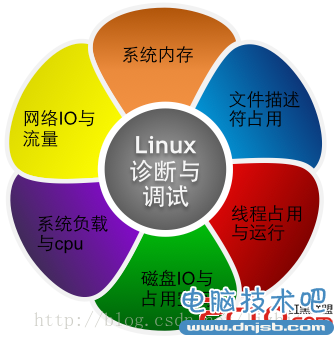
笔者从上述6个方面扩展到多个维度剖析,应用程序或服务出现问题的症状所在,正因为互联网公司特殊性,技术工程师流动相对比较频繁,岗位变更交接等原因,造成了后来接手人(新手)无法及时应对线上出现各种状况。或因为经验不足,或因为对线上情况不了解等,增加了很多不确定因素。如果我们有一套简单通用可行检测和衡量规则,就大大降低风险。希望能通过这个参考手册的帮助,分析大量在线参数数据并从中找到蛛丝马迹,也能缩小排查有问题程序的范围。
正因为程序出现问题需要诊断和调试,那需要通过分析和判断哪些方面因素会引起linux性能波动。
孙子.谋攻
知己知彼,百战不殆;
不知彼而知己,一胜一负;
不知彼,不知己,每战必殆。
影响Linux性能因素
操作系统CPU
内存
磁盘I/O及性能
网络I/O状况及性能
linux系统性能评估标准
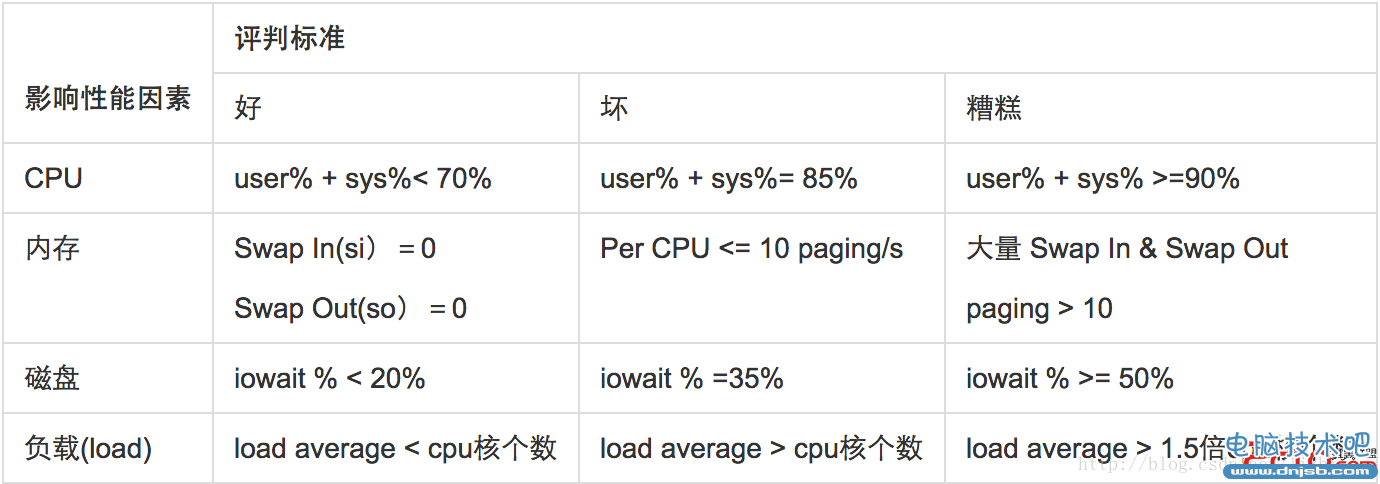
注:关于swap和paging含义后面有名称解释
linux 系统性能分析命令或工具
常用命令:
dstat,vmstat、sar、iostat、netstat、free、ps、top等
性能分析和诊断工具
用vmstat、sar、iostat检测是否是CPU、磁盘,内存瓶颈用free、vmstat检测是否是内存、IO瓶颈
用iostat检测是否是磁盘I/O瓶颈
用dstat检测是否是网络带宽、磁盘io、内存、负载等综合瓶颈分析
用mpstat检测是否cpu调用不均衡,也可以使用top替代
用pidstat检测相应进程cpu消耗情况
用netstat检测socket buffer有未发送或处理的数据,从而判断程序处理能力下降或出现问题.
用lsof检测打开文件描述(网络文件和磁盘文件,管道等)符过多,导致资源不足
用df和du组合检测挂载磁盘或目录占用空间巨大或inode节点消耗殆尽。
用iftop检查2台主机间是否存在流量瓶颈.
下面命令中参数名词解释:
buffer是用于存放(缓存)要输出到disk(块设备)的数据的,
cache是存放从disk上读出的数据。这buffer和cache是为了提高IO性能的,并由OS管理。
swap: linux内核读写虚拟内存是以 “页” 为单位操作的,把内存转移到硬盘交换空间(SWAP)和从交换空间读取到内存 的时候都是按页来读写的。
Paging:内存和SWAP的这种交换过程称为页面交换(Paging)
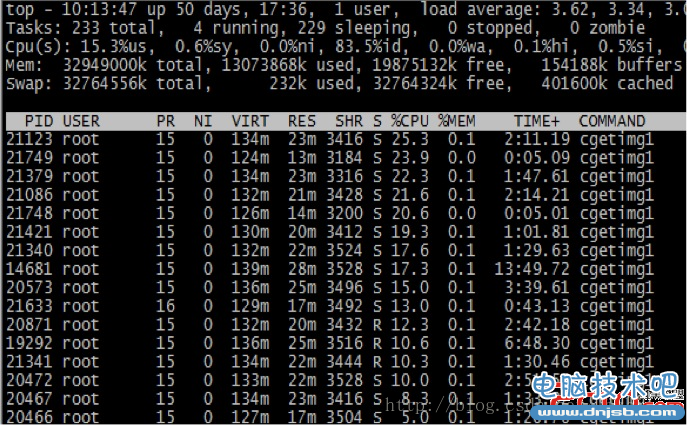
Linux - top
top
shift + h 按线程查看cpu消耗情况查看每个核消耗情况
us 过高说明应用程序消耗了大部分cpu
sy 过高表示系统线程切换频繁
wa 表示为在执行过程中等待io所占的百分比 hi 硬件中断(ex:网卡接收数据频发)
top -p pid 多列信息列表中直显示对应进程信息.
Linux - free
free -m

-/+ buffers/cache
used应用程序总共使用的内存数=Mem.used-Mem.buffers-Mem.cached
应用程序还未使用的内存数=Mem.free+Mem.buffers+Mem.cached
上面是free -m的运行结果,一共有4行。为了方便说明,笔者加上了列号。这样可以把free的输出看成一个二维数组rowcols(Free Output),下面可以使用2个等式表示两个等式
rowcols[3][2] = rowcols[2][2] - rowcols[2][5] - rowcols[2][6]
rowcols[3][3] = rowcols[2][3] + rowcols[2][5] + rowcols[2][6]
注:free命令中内存参数与top中第四行,五行--对应,top就是少了free第三行参数值
Linux - netstat / ss
netstat –an | grep 端口

Recv-Q 网络接收队列 一般情况为0,如果持续为非0表示收到的数据已经在本地接收缓冲,应用程序还没处理,可能是应用程序处理性能下降。
Send-Q 发送队列 一般情况为0,如果持续为非0可能是应用向外发送数据包过快,或者是 对方接收数据包不够快。
netstat –an | grep 端口 (查看应用程序端口是否正常监听)
以前遇到过分布式缓存memcached在高峰访问中会出现这种现象,由于高峰时期极端情况下多线程lock内存池原因,导致服务端性能急剧下降。
Linux - vmstat
vmstat 1 10
vmstat CPU使用率,内存使用,虚拟内存交换情况,IO读写情况
一般使用格式为:vmstat interval count //表示输出频率1秒,连续输出10次
使用实例: vmstat 1 10
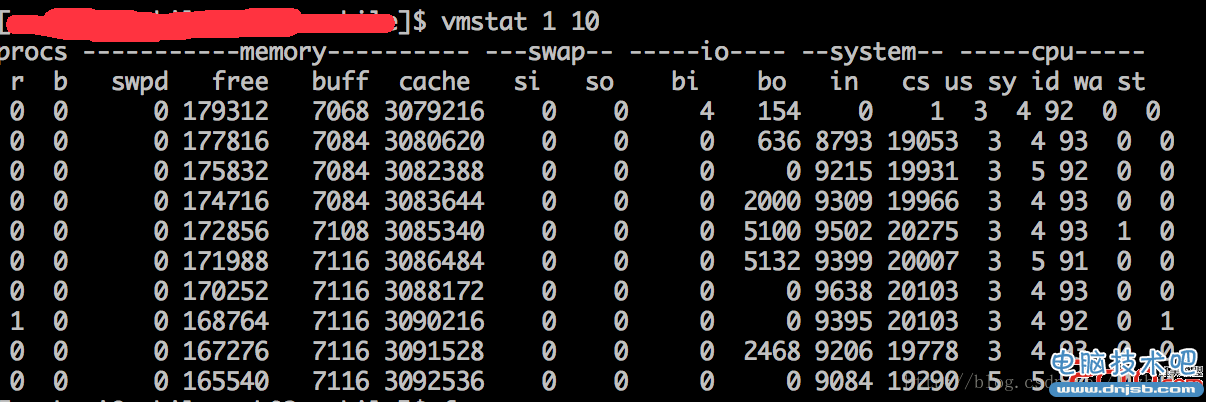
如果CPU的sy和us值相加的百分比接近100%,或者运行队列(r)中等待 的进程数总是不等于0,且经常大于4,同时id也经常小于40,则该系 统受限于CPU;如果bi、bo的值总是不等于0,则该系统受限于内存。 swpd值过高一般情况由于物理内存不够用.
free列表示当前空闲的物理内存数量(以k为单位)buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
memory
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。in 每秒CPU的中断次数
cs 每秒上下文切换次数 //如果上下文切换过多(远高于平常数值),则可能是线程创建过多
us 用户CPU时间占百分比
sy 系统CPU时间占百分比
id 空闲 CPU时间占百分比
wt 等待IO
Linux - sar
sar 1 10
格式如下:sar -d interval count
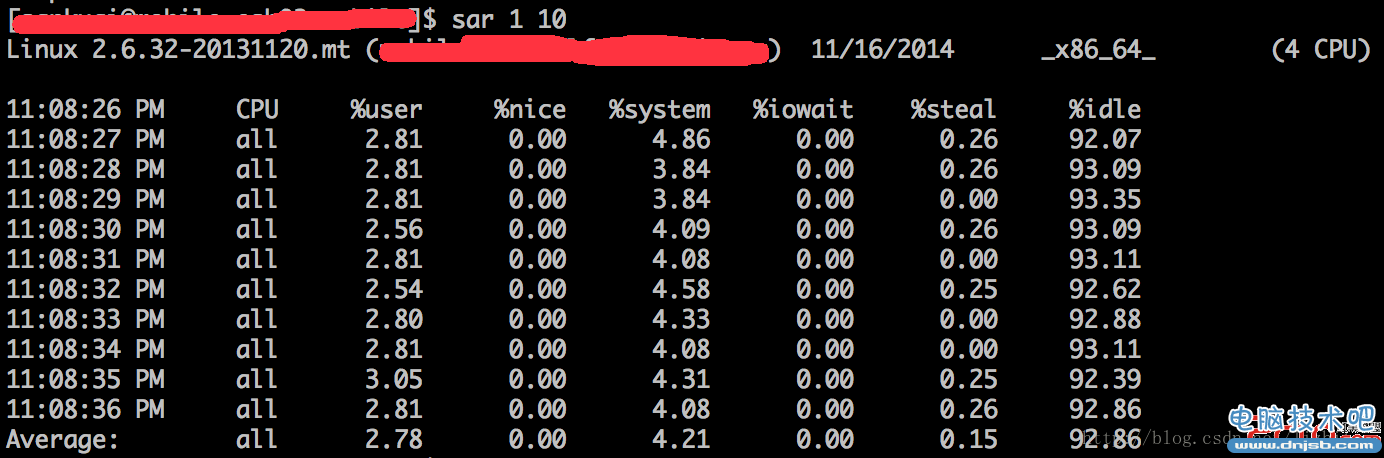
需要关注几个参数:
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。
利用sar作性能评估
磁盘IO性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
Linux - iostat
iostat 1 10
iostat interval cont
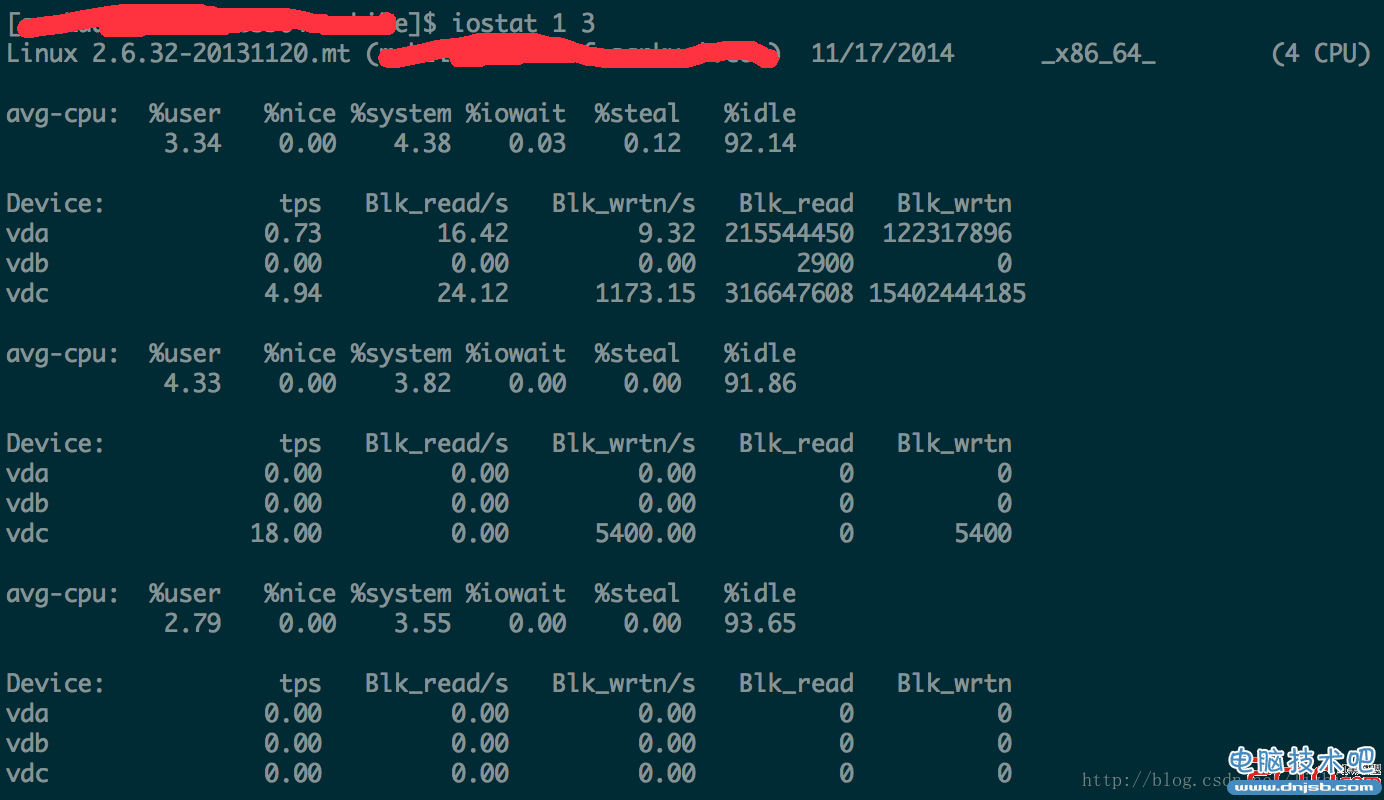
上面每项的输出解释如下:
平均百分比为 = 总cpu占百分比/cpu核心数
%user 表示平均处理用户进程所使用 CPU 的百分比。%nice 表示平均使用 nice 命令对进程进行降级时 CPU 的百分比。在之前的部分中已经对nice命令进行了介 绍。简单来说,nice命令更改进程的优先级。
%system 表示平均内核进程使用的CPU百分比
%iowait 表示平均等待进行 I/O 所使用的CPU时间百分比
%irq 表示用于处理系统中断的CPU百分比
%steal 表示列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的s
%idle 显示CPU的空闲时间百分比
Blk_read/s 表示每秒读取的数据块数。
Blk_wrtn/s 表示每秒写入的数据块数。
Blk_read 表示读取的所有块数。
Blk_wrtn 表示写入的所有块数。
可以通过Blk_read/s和Blk_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果Blk_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
Linux - mpstat
mpstat -P ALL 1 10
格式如下:mpstat -P ALL interval count
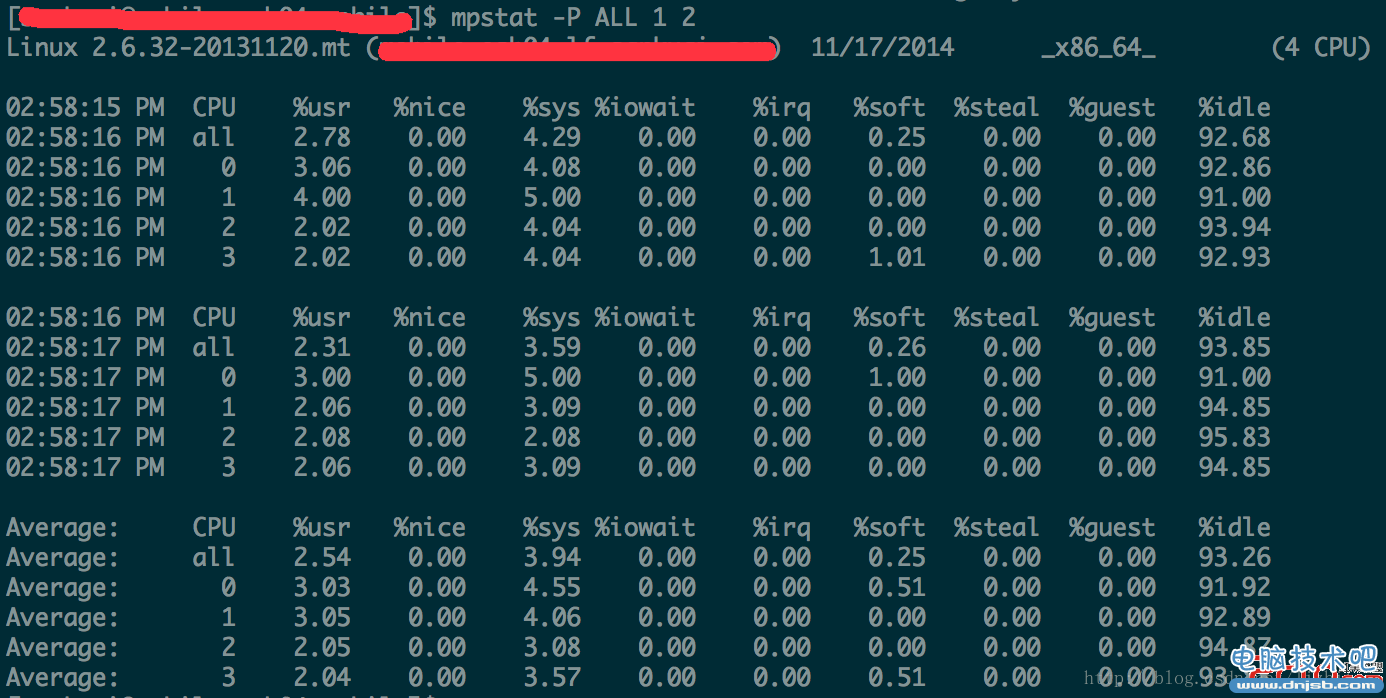
它显示了系统中CPU的各种统计信息。–P ALL 选项指示该命令显示所有 CPU 的统计信息.
%user 表示处理用户进程所使用 CPU 的百分比。%nice 表示使用 nice 命令对进程进行降级时 CPU 的百分比。在之前的部分中已经对nice命令进行了介绍。简单来 说,nice命令更改进程的优先级。
%system 表示内核进程使用的 CPU 百分比
%iowait 表示等待进行 I/O 所使用的 CPU 时间百分比
%irq 表示用于处理系统中断的 CPU 百分比
%steal 表示列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的s
%idle 显示CPU的空闲时间百分比
Linux - dstat
dstat -tcdnmlpygs 1 10
格式:dstat -tcdnmlpygs interval count

dstat是多功能系统资源统计工具
dstat具体参数说明就不列出了,上述其他命令已经有说明
在获取的信息上有点类似于top、free、iostat、vmstat等多个工具的合集.
CPU状态:CPU的使用率磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络流量统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动
系统统计:这一项显示的是中断(int)和上下文切换(csw)
内存统计:这一项列出应用程序已使用物理内存,buffer,cache,free空闲内存
linux - iftop
iftop
iftop显示了系统上所有源主机或者目的主机网络带宽使用的列表,此列表定期更新。
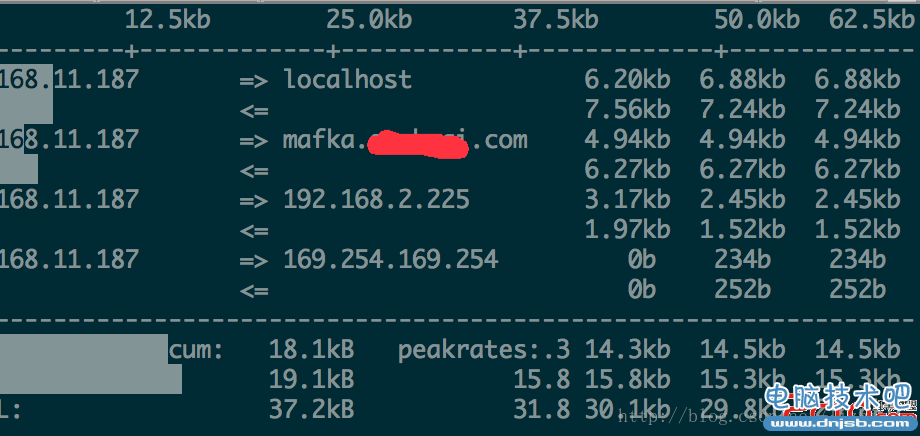
iftop部分参数说明与解释
主机显示n: 切换是否解析主机名,你可以选择显示域名还是 IP 地址;
s/d: 切换是否显示源主机或者目的主机;
t: 切换主机接收和发送显示的模式:两行显示、一行显示、只显示发送流量、只显示发送流量;
端口显示
N: 切换显示服务名称还是端口号,例如 ssh 或者 22;
S/D:切换是否显示源主机端口或者目的主机端口;
p:切换是否显示端口号;
排序显示
1/2/3:根据最近 2 秒、10 秒、40 秒的平均网络流量排序;
<:根据源主机地址排序;
>:根据目的主机地址排序;
o:固定显示当前连接,用来观察当前连接的流量情况,避免刷新后连接顺序变化;
下面部分含义
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s 10s 40s 的平均流量
linux - df & du
查看磁盘空间使用、挂载和inode情况
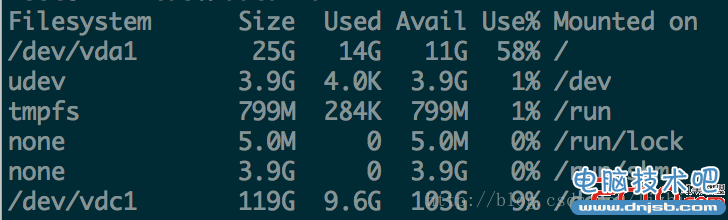
du命令查看文件和目录磁盘使用的空间
输出当前目录下各个子目录所使用的空间:du -h --max-depth=1
按照子目录大小排序(降序):du -s * | sort -rn | cut -f2- | xargs -d "/n" du -sh
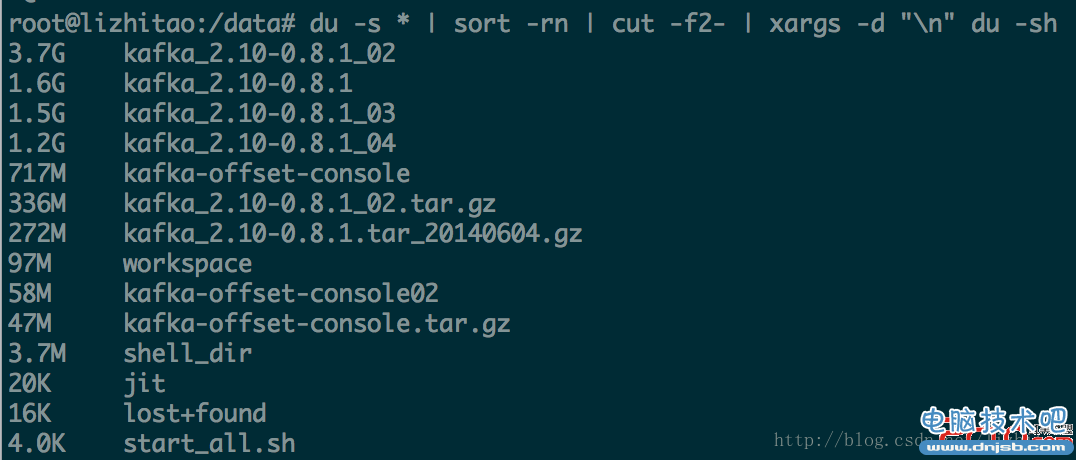
linux诊断与调试部分命令使用汇总
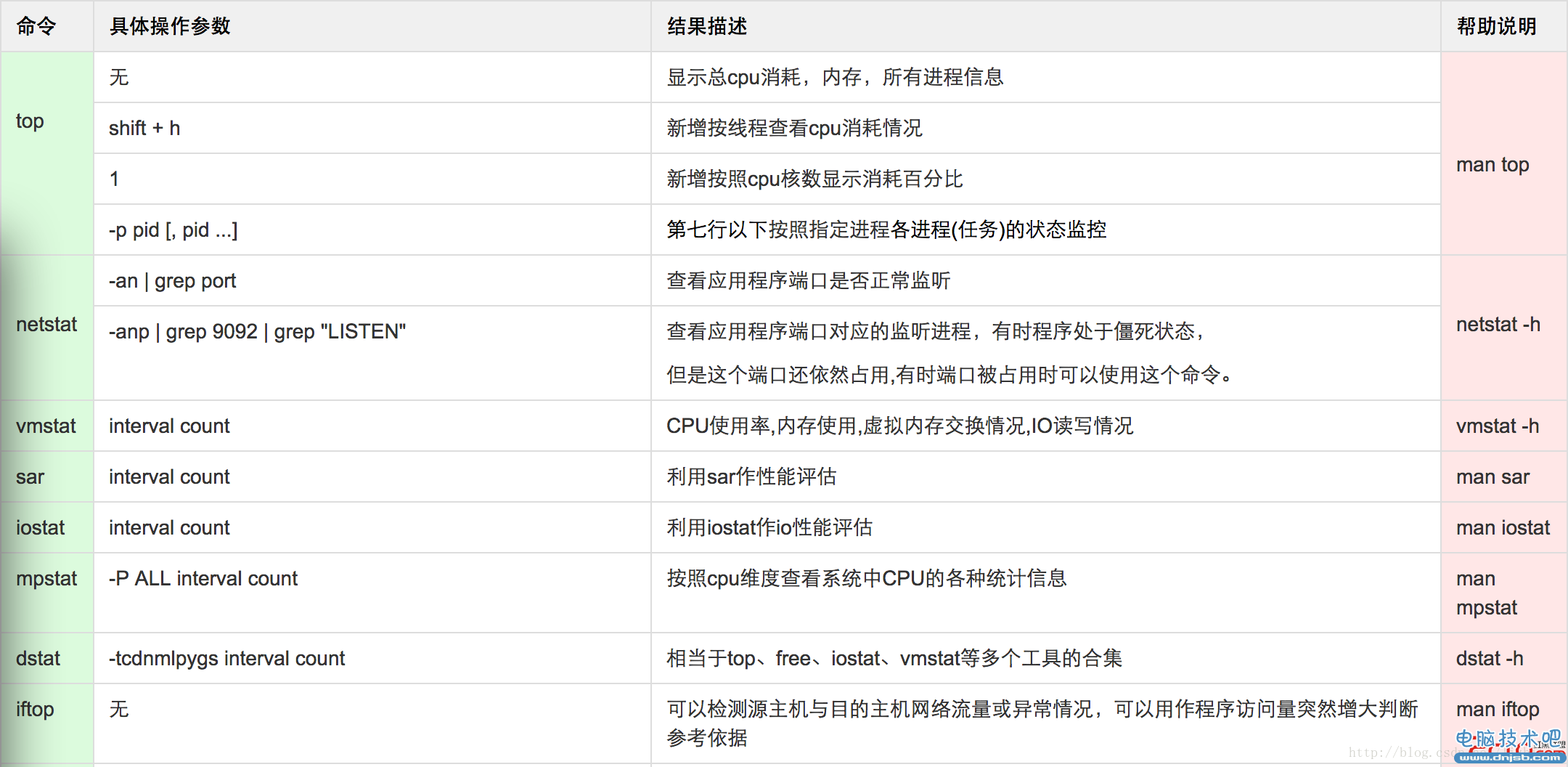
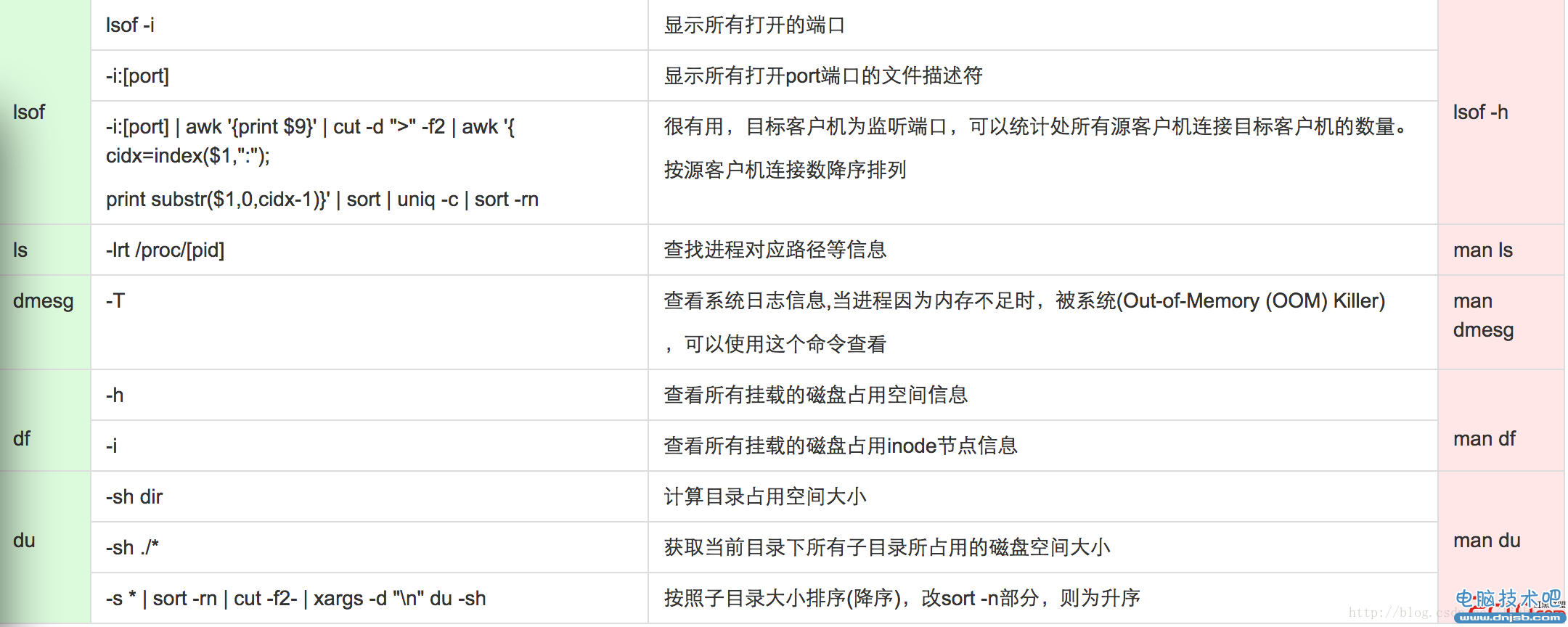
lsof -i:9092 | awk '{print $9}' | cut -d ">" -f2 | awk '{ cidx=index($1,":");print substr($1,0,cidx-1)}' | sort | uniq -c | sort -rn
案例剖析
案例1 创建大量网络连接数导致服务进程挂死或假死
当某台或几台机器作为基础服务组件或中间件节点(不一定为java,或python,go,c/c++等等)集群部署时,会有大量客户端会依赖此服务而连接此目标集群。笔者遇到真实情况,集群正常运行好长一段时间后,有一天突然发现集群中某个节点处于不可用状态。观察其应用程序日志没有任何错误信息,而且服务程序却无法正常对外提供响应。
笔者通过相关命令按照以上几个法则(cpu,内存,磁盘io,网络io,网络流量),当我们查看cpu,io,网络流量,磁盘容量,
发现监听端口连接数数量巨大,存在问题,经定位分析发现某台客户端主机创建大量网络连接没有释放。一般情况下linux系统最大文件描述数量设置都非常大,到达100W以上,多数是其他资源先消耗。
下面是模拟当时环境的一幅图。
[lizhitao@host ] netstat -an | grep 9094
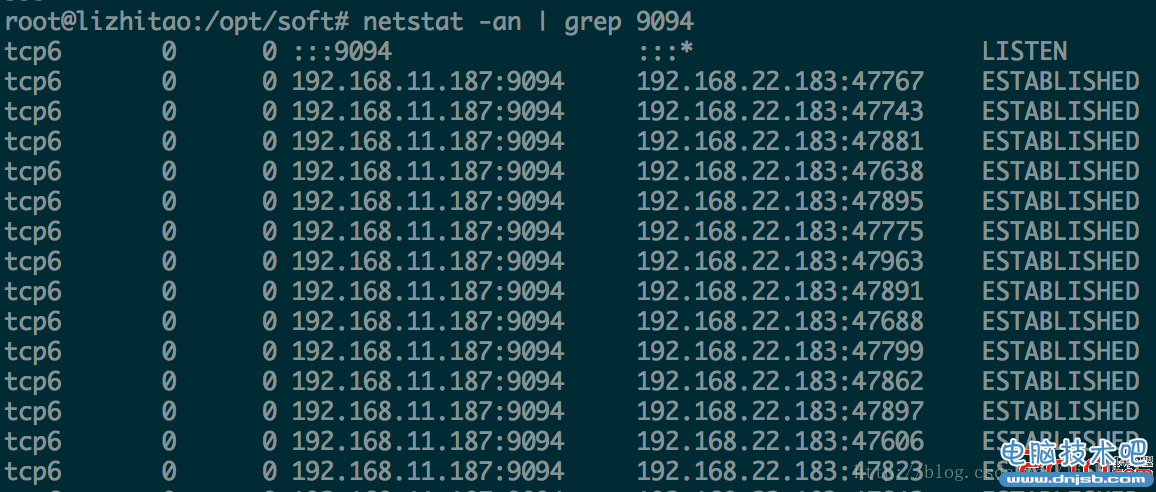
[lizhitao@host ] lsof -i:9094 | awk '{print $9}' | cut -d ">" -f2 | awk '{ cidx=index($1,":");print substr($1,0,cidx-1)}' | sort | uniq -c | sort -rn

很明显mafka.sankuai.com这台主机创建了大量连接,导致资源耗尽。
说明:netstat一般显示是ip,lsof一般显示主机名,因为客户端连接比较多(在TCP里好像每个socket占用500byte),很难一下子看出哪个客户主机数比较多,所以2命令组合使用就比较方便。
扩展阅读:
上面案例是网络连接(网络文件描述符)问题,而有些可能是磁盘文件(描述符)打开量巨大,而没有释放资源导致程序bug。
典型就是存储图片或小文件的分布式文件系统。
递归查找某个目录中所有打开的文件[lizhitao@host ] lsof +D /DIR/
lsof的列表中Type为REG和DIR分别表示打开磁盘文件和目录
[lizhitao@host ] lsof -p [pid] | "REG" //列举该进程所有打开的磁盘文件.
然后通过计算和分析就能知道是否有大量磁盘文件没有释放,然后定位出问题的代码块.
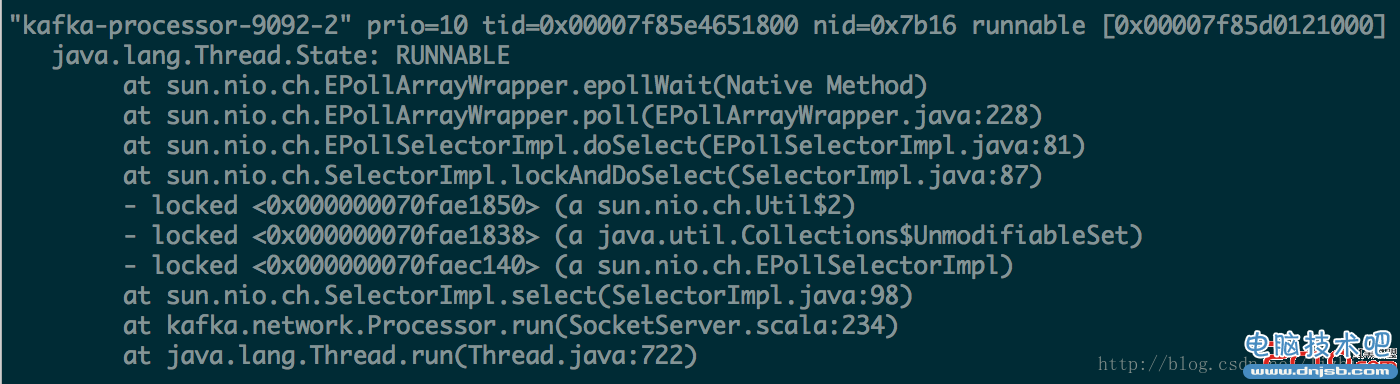
案例2 线上java服务进程突然cpu占用很高。
java进程cpu的消耗排序
[lizhitao@host ] ps p 31476 -L -o pcpu,pid,tid,time,tname,stat,psr | gawk '{printf("%s %d %d %s %s %s %x/n",$1,$2,$3,$4,$5,$6,$3) }' | sort -n -k1 -r
假如上述图片列表中显示的cpu消耗很高且大约80%cpu,则我们可以通过上述命令操作,找到对应线程号nid=31510转换为十六进制0x7b16
[lizhitao@host ] jstack 31476 | grep "7b16"

[lizhitao@host ] jstack 31476
缩小代码排查范围,顺藤摸瓜找到对应的调用堆栈信息和代码,然后对相关代码逻辑进行分析。
案例3 某个进程启动时无法创建文件
如果遇到上述错误,可以先检测一下硬盘状态信息(一般是这类问题概率不大,除非是数据库或做存储用的服务器)
请参考硬盘检测smartctl:Linux系统下检测硬盘的健康状态
Linux硬盘的检测
如果磁盘状态一切正常,则分析可能为挂载磁盘空间占满。
执行 :df -h 查看磁盘空间占用情况
然后到相应的应用程序软件部署目录或数据存储目录下执行:
du -s * | sort -rn | cut -f2- | xargs -d "/n" du -sh
就可以顺利找到占用空间比较大的目录,然后做相应处理。
总结
以上,就是我在linux下后端诊断与调试时遇到的问题和收获,以及解决办法,下面是我对这些方面的总结:
linux下后端诊断与调试是复杂而比较有挑战性工作,需要操作者或工程师综合运用各种手段找到问题所在,从而逐步地缩小范围,定位到某个点上,不同的应用程序也会不一样,比如说:普通的java(tomcat)服务与memcached分布式缓存遇到问题也不尽相同。首先我们可以从系统层面上划清界限,是操作系统,本机服务程序,还是其他主机访问导致的。通过六种手段,比如说网络io,磁盘io,内存,cpu,打开文件,线程等,分析其瓶颈方向。所以没有一种命令或方法能“包治百病”,需要工程师在不同应用环境下,巧妙选择且综合运用不同手段,搭配多种命令组合才能完成。
相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












