图解几个与Linux网络虚拟化相关的虚拟网卡-VETH/MACVLAN/MACVTAP/IPVLAN
发布时间:2015-05-27 19:09:55作者:知识屋
这些对网络虚拟化的支持技术包括任何重量级的虚拟化技术,比较重的比如对虚拟机技术的支持,轻量级的则是net namespace技术。近期的工作基于net namespace技术,关于这个技术我也不多说了,它主要是提供了每个namespace独立的协议栈以及网卡,对于网络协议栈以及网卡之外的部分,所有namespace是共享的,这种轻量级的针对网络的虚拟化技术对于模拟多客户端网络连接特别有用而且操作简单。我会单独写一篇文章来展示这种操作。
如果仅仅为了完成工作,那么我不会写这篇文章,早在去年的时候,我写过一篇关于net namespace的,根据那个里面的step by step,工作就已经可以完成了,并且在去年年末到今年年初,这个工作我们也已经做过了,然而对于学习而言,就不是这样了。学习应该是碰到一点折腾一点,我知道,很多人都知道,现在不比上学那会儿了,我们谁都没有整块的时间系统地进行学习,特别是对于我这种结了婚有了孩子,需要为了还贷款而不再任性的路人丙来讲,更是这样。因此就需要对所碰到的技术有一种可遇而不可求的相见恨晚的感觉,这样就有动力把它吃透了。
本文中,我想通过几张图来介绍一下Linux中常用的几类和网络虚拟化相关的虚拟网卡,当然,这些虚拟网卡的使用场景并不仅限于net namespace,重量级的虚拟机也可以使用,之所以用net namespace举例是因为它的简单性。总体来说,这些虚拟网卡的原理就摆在那里,具体在什么场景下使用它们,就看你自己的想象力了。
网络虚拟化
总体来讲,所谓的网络虚拟化在本文中指的是主机中的网络虚拟化,侧重于在一台物理主机中,分离出多个TCP/IP协议栈的意思。网络虚拟化可以独立实现,也可以依托别的技术实现。在Linux中,独立的网络虚拟化实现就是net namespace技术,依托别的技术实现的网络虚拟化就是虚拟机技术,我们当然知道,每个虚拟机里面都有自己的协议栈,而这种依托虚拟机技术实现的网络虚拟化可能还要更简单一些,因为宿主机并不需要去“实现”一个协议栈,而是把这个任务交给了虚拟机的操作系统来完成,宿主机“相信”虚拟机里面一定运行着一个拥有协议栈的操作系统。理解虚拟网卡的要旨
你要知道,一块网卡就是一道门,一个接口,它上面一般接协议栈,下面一般接介质。最关键的是,你要明确它们确实在上面和下面接的是什么。由于网卡的上接口在OS中实现,或者使用PF技术在用户态实现,总而言之,它们是软的,这就意味着你可以任意实现它们。反之,下接口便不受机器运行软件的控制了,你无法通过软件改变双绞线的事实,不是吗?故此,我们一般关注网卡下面接的是什么,是什么呢?姑且将它叫做endpoint吧。在开始正文之前,我先列举几个常见的endpoint:
以太网ETHx:普通双绞线或者光纤;
TUN/TAP:用户可以用文件句柄操作的字符设备;
IFB:一次到原始网卡的重定向操作;
VETH:触发虚拟网卡对儿peer的RX;
VTI:加密引擎;
...
关于数据在宿主网卡和虚拟网卡之间的路由(广义的路由),有很多方式,在早期的内核中,对bridge(Linux的bridge也算是一种虚拟网卡)的支持是靠一个在netif_receive_skb中硬编码调用的一个br_handle_frame_hook钩子来实现的,这个钩子由bridge模块注册。但是随着虚拟网卡种类的越来越多,总不能每一种都硬编码这么一种钩子,这样会使得netif_receive_skb显得太臃肿,因此一种新的方式被提出来了,事实上很简单,就是将这种钩子向上抽象了一层,不再硬编码,而是统一在netif_receive_skb中调用唯一的一个rx_handler的钩子。具体如何设置这种钩子,就看这个宿主网卡需要绑定哪种类型的虚拟网卡了,比如:
对于bridge:调用netdev_rx_handler_register(dev, br_handle_frame, p),在netif_receive_skb中调用的是br_handle_frame;
对于bonding:调用netdev_rx_handler_register(slave_dev, bond_handle_frame, new_slave),在netif_receive_skb中调用的是bond_handle_frame;
对于MACVLAN:调用netdev_rx_handler_register(dev, macvlan_handle_frame, port),在netif_receive_skb中调用的是macvlan_handle_frame;
对于IPVLAN:调用netdev_rx_handler_register(dev, ipvlan_handle_frame, port),在netif_receive_skb中调用的是ipvlan_handle_frame;
对于...
每一块宿主网卡只能注册一个rx_handler,但是网卡和网卡却可以叠加。
VETH虚拟网卡技术
关于这个虚拟网卡,我在《OpenVPN多处理之-netns容器与iptables CLUSTER》中有提到过,每一个VETH网卡都是一对儿以太网卡,除了xmit接口与常规的以太网卡驱动不同之外,其它的几乎就是一块标准的以太网卡。VETH网卡既然是一对儿两个,那么我们把一块称作另一块的peer,标准上也是这么讲的。其xmit的实现就是:将数据发送到其peer,触发其peer的RX。那么问题来了,这些数据如何发送到VETH网卡对儿之外呢?自问必有自答,自答如下:1.如果确实需要将数据发到外部,通过将一块VETH网卡和一块普通ETHx网卡进行bridge,通过bridge逻辑将数据forward到ETHx,进而发出;
2.难道非要把数据包发往外部吗?类似loopback那样的,不就是自发自收吗?使用VETH可以很方面并且隐秘地将数据包从一个net namespace发送到同一台机器的另一个net namespace,并且不被嗅探到。
VETH虚拟网卡非常之简单,原理图如下所示:
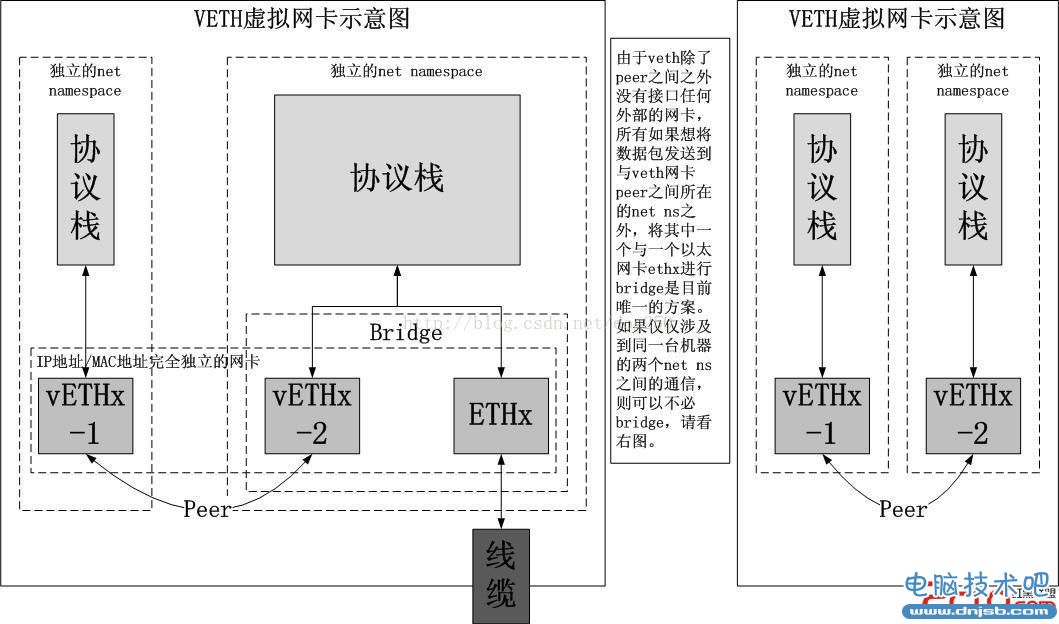
VETH使用原始朴素的方式连接了不同的net namespace,符合UNIX的风格,因此你需要动用很多别的技术或者工具来完成net namespace的隔离以及数据的发送。
MACVLAN虚拟网卡技术
MACVLAN技术可谓是提出一种将一块以太网卡虚拟成多块以太网卡的极简单的方案。一块以太网卡需要有一个MAC地址,这就是以太网卡的核心中的核心。以往,我们只能为一块以太网卡添加多个IP地址,却不能添加多个MAC地址,因为MAC地址正是通过其全球唯一性来标识一块以太网卡的,即便你使用了创建ethx:y这样的方式,你会发现所有这些“网卡”的MAC地址和ethx都是一样的,本质上,它们还是一块网卡,这将限制你做很多二层的操作。有了MACVLAN技术,你可以这么做了。
我们先来看一下MACVLAN技术的流程示意图:
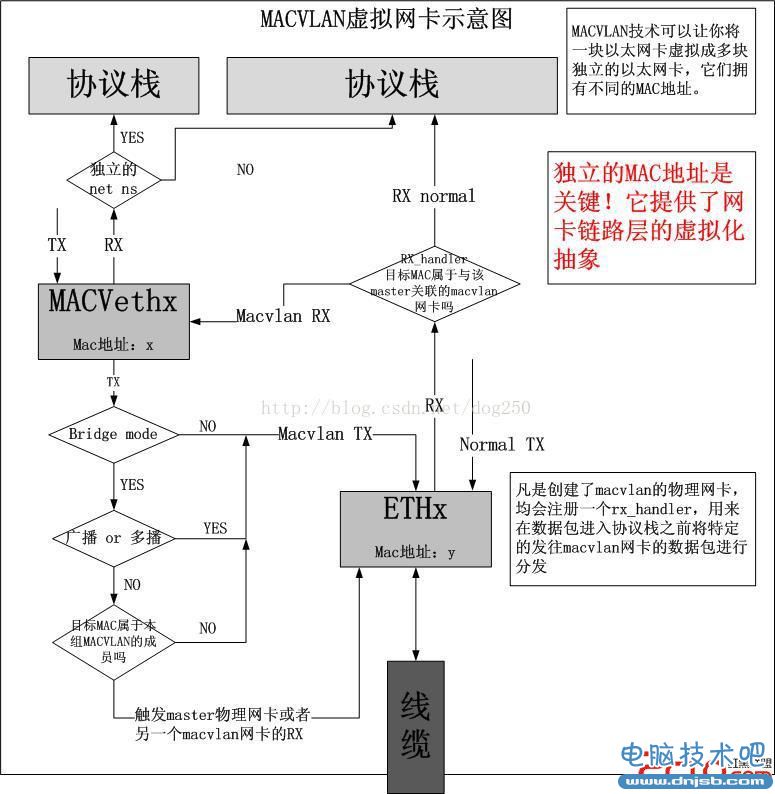
在具体的执行上,通过下面的命令,你可以创建一个MACVLAN网卡,它是基于eth0虚拟出来的:
ip link add link eth0 name macv1 type macvlan
你可以认为有人将双绞线“物理上”每根一分为二,接了两个水晶头,从而连接了两块网卡,其中一块是虚拟的MACVLAN网卡。但是既然共享介质,难道不用运行CSMA/CD吗?当然不用,因为事实上,最终的数据是通过eth0发出的,而现代的以太网卡工作的全双工模式,只要是交换式全双工(某些标准而言,这是必须的),eth0自己能做好。
现在可以说一下MACVLAN技术构建的虚拟网卡的模式了。之所以MACVLAN拥有所谓的模式,是因为相比VETH,它更是将复杂性建立在了一个已经容不下什么的以太网概念上,因此相互交互的元素就会太多,它们之间的关系不同,导致最终MACVLAN的行为不同。还是图解的方式:
1.bridge模式
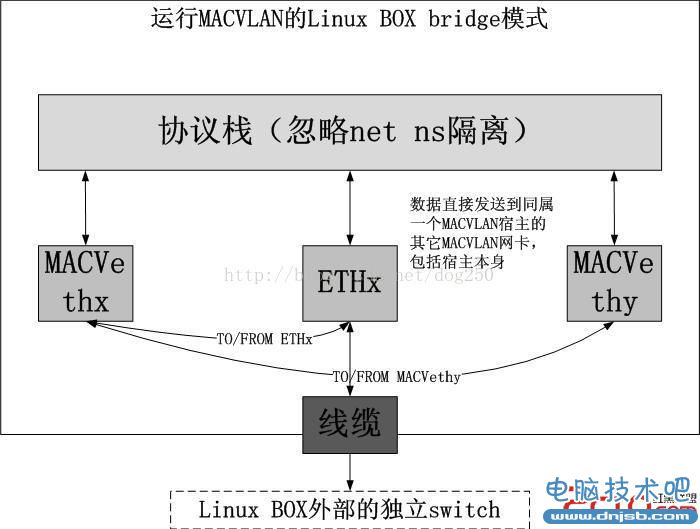
这个bridge只是针对同属于一块宿主以太网卡的MACVLAN网卡以及宿主网卡之间的通信行为的,与外部通信无关。所谓的bridge指的是在这些网卡之间,数据流可以实现直接转发,不需要外部的协助,这有点类似于Linux BOX内建了一个bridge,即用brctl命令所做的那一切。
2.VEPA模式
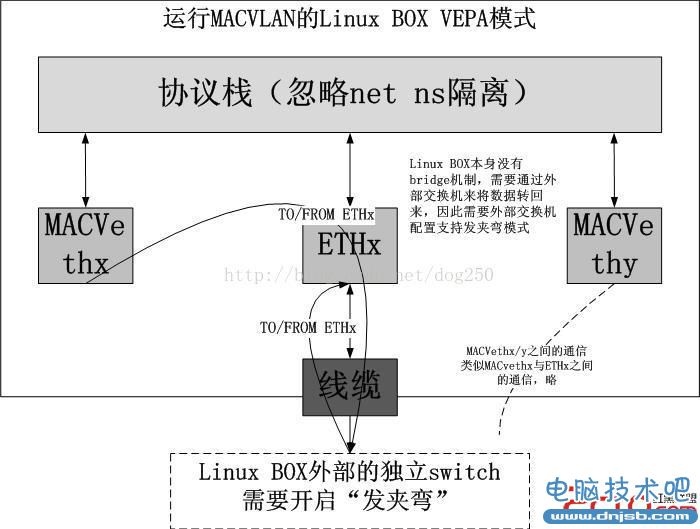
VEPA模式我后面会专门讲。现在要知道的是,在VEPA模式下,即使是MACVLANeth1和MACVLANeth2同时配在在eth0上,它们两者之间的通信也不能直接进行,而必须通过与eth0相连的外部的交换机协助,这通常是一个支持“发夹弯”转发的交换机。
3.private模式
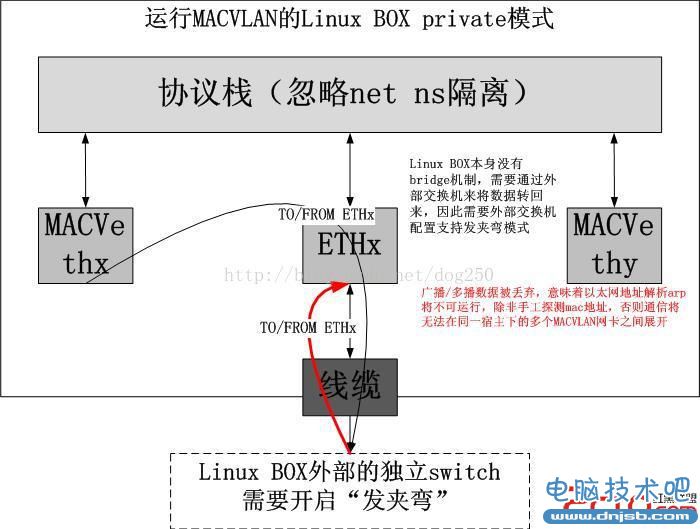
这种private模式的隔离强度比VEPA更强。在private模式下,即使是MACVLANeth1和MACVLANeth2同时配在在eth0上,eth0连接了外部交换机S,S支持“发夹弯”转发模式,即便这样,MACVLANeth1的广播/多播流量也无法到达MACVLANeth2,反之亦然,之所以隔离广播流量,是因为以太网是基于广播的,隔离了广播,以太网将失去了依托。
如果你想配置MACVLAN的模式,请在ip link命令后面添加mode参数:
ip link add link eth0 name macv1 type macvlan mode bridge|vepa|private
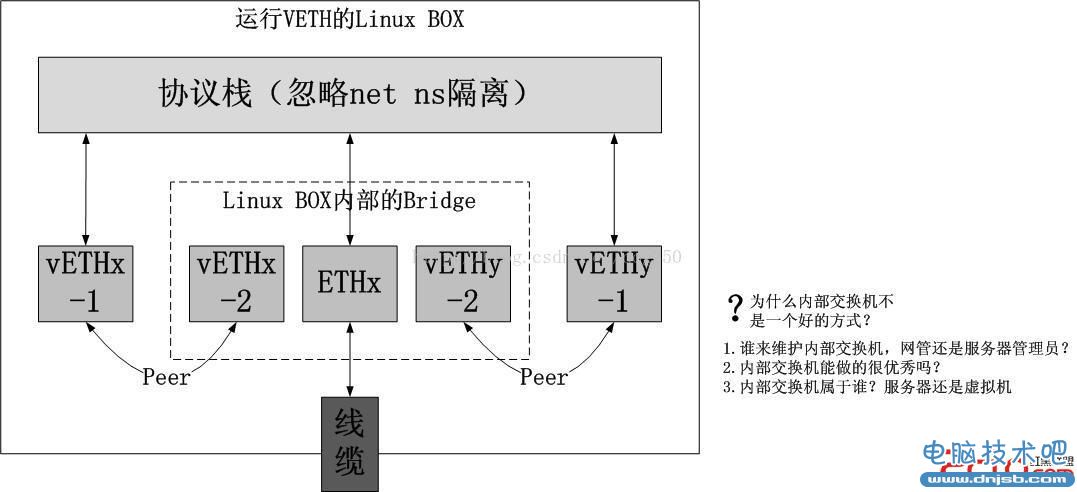
VETH网卡与MACVLAN网卡之间的异同
我们先看一下如何配置一个独立的net namespace。1.VETH方式
ip netns add ns1ip link add v1 type veth peer name veth1
ip link set v1 netns ns1
brctl addbr br0
brctl addif br0 eth0
brctl addif br0 veth1
ifconfig br0 192.168.0.1/16
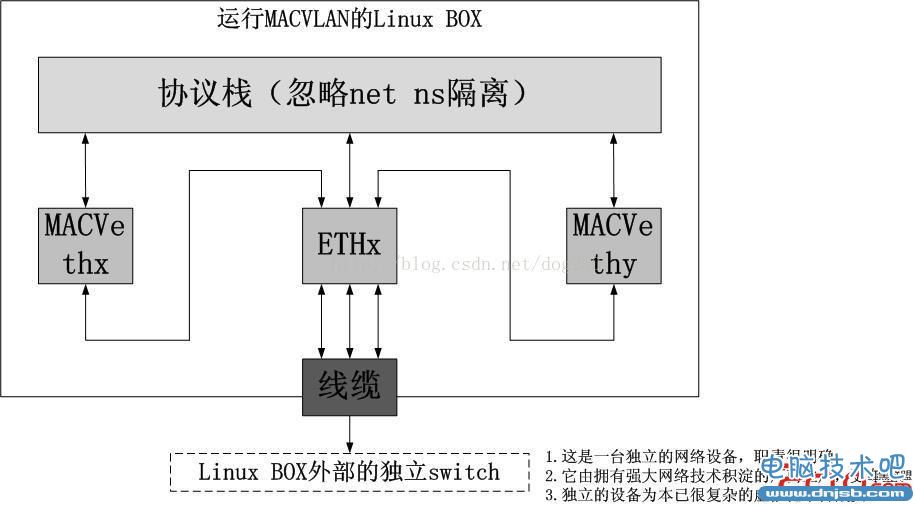
2.MACVLAN方式
ip link add link eth0 name macv1 type macvlanip link set macv1 netns ns1
可以看到,MACVLAN做起同样的事,比VETH来的简单了。那么效率呢?Linux的bridge基于软件实现,需要不断查找hash表,这个同样也是MACVLAN bridge模式的做法,但是VEPA模式和private模式下,都是直接转发的。它们的区别可以从下图展示出来:
VEPA技术
VEPA是什么?Virtual Ethernet Port Aggregator。它是HP在虚拟化支持领域对抗Cisco的VN-Tag的技术。所以说,Cisco的VN-Tag和VEPA旨在解决同一个问题或者说同一类问题。解决的是什么问题呢?通俗点说,就是虚拟机之间网络通信的问题,特别是位于同一个宿主机内的虚拟机之间的网络通信问题。难道这个问题没有解决吗?我使用的VMWare可以在我的PC中创建多个虚拟机,即便我拔掉我的PC机网线,这些虚拟机之间也能通信...VMWare内部有一个vSwitch。就是说,几乎所有的虚拟机技术,内置的交叉网络都能解决虚拟机之间的通信问题。那么还要VN-Tag以及VEPA干什么?
这个问题涉及到两个领域,一个是扩展性问题,另一个是职责边界问题。说明白点就是,内置的vSwitch之类的东西在性能和功能上足以满足要求吗?它属于虚拟机软件厂商的边缘产品,甚至说不是一个独立的产品,它一般都是附属虚拟机软件赠送的,没有自己的销售盈利模式,虚拟机厂商之所以内置它是因为它只是为了让用户体验到虚拟机之间“有相互通信的能力”,所以厂商是不会发力将这种内置的虚拟交换机或者虚拟路由器做完美的,它们推的是虚拟机软件本身。
另外,千百年来,网络管理员和系统管理员之间的职责边界是清晰的,直到到达了虚拟化时代。如果使用内置的虚拟交换机,那么如果这个交换机出了故障或者有复杂的配置任务计划,找谁呢?要知道这个虚拟交换机内置于宿主服务器内部,这是系统管理员的领域,一般的网管设置无法触摸到这些设备,数据中心复杂的三权分立管理模式也无法让网管去登录服务器。反过来,系统管理员对网络协议的认知程度又远远比不上专业网管。这就造成了内置于虚拟机软件的虚拟网络设备的尴尬处境。另一方面,这个虚拟的网络设备确实不是很专业的网络设备。爆炸!
Cisco不愧为网络界的大咖。它总是在出现这种尴尬场景的时候率先提出一个标准,于是它改造了以太网协议,推出了VN-Tag,就像ISL之于IEEE802.1q那样。VN-Tag在标准的协议头中增加了一个全新的字段,这种做法的前提是Cisco有能力用最快的速度推出一款设备并让其真正跑起来。在看看HP的反击,HP没有Cisco那样的能力,它不会去修改协议头,但是它可以修改协议的行为从而解决问题,虽然比Cisco晚了一步,但是HP提出的VEPA不愧是一种更加开放的方式,Linux可以很容易的增加对其的支持。
VEPA,它很简单,一个数据包从一个交换机的一个网口进入,然后从同一个网口发回去,好像是毫无意义的做法,但是它却没有改变以太网的协议头。这种做法在平常看来真的是毫无意义的,因为正常来讲,一块网卡连接一根网线,如果是自己发给自己的数据,那么这个数据是不会到达网卡的,对于Linux而言,直接就被loopback给bypass了。但是对于虚拟化场景而言,情况就有所不同了,虽然物理宿主机上可能拥有一块以太网卡,但是从该网卡发出的数据包却不一定来自同一个协议栈,它可能来自不同的虚拟机或者不同的net namespace(仅针对Linux),因为在支持虚拟化OS的内部,一块物理网卡被虚拟成了多块虚拟网卡,每一块虚拟网卡属于一个虚拟机...此时,如果不修改以太网协议头且又没有内置的虚拟交换机,就需要外部的一台交换机来协助转发,典型的就是从一个交换口收到数据包,把它从该口再发出去,由宿主网卡决定是否接收以及如何接收。如下图所示:
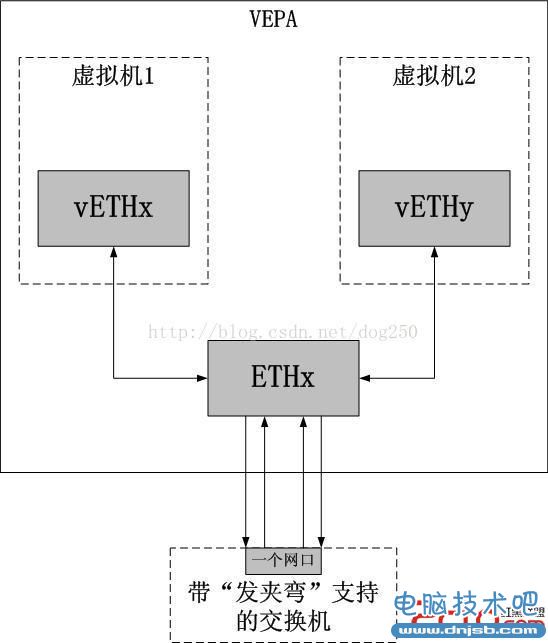
对于以太网卡而言,硬件上根本就不需要任何修改,软件驱动修改即可,对于交换机而言,需要修改的很少,只要在MAC/Port映射表查询失败的情况下,将数据包广播到包括入口的所有端口即可,对于STP协议,也是类似的修改。对于HP而言,发出VEPA是一个正确的选择,因为它不像Cisco和Intel那样,可以大量生产网卡和设备,从而控制硬件标准。对于支持VEPA的交换机而言,仅仅需要支持一种“发夹弯”的模式就可以了。爆炸!
IPVLAN虚拟网卡技术
这个小节我们来看下IPVLAN。在理解了MACVLAN之后,理解IPVLAN就十分容易了。IPVLAN和MACVLAN的区别在于它在IP层进行流量分离而不是基于MAC地址,因此,你可以看到,同属于一块宿主以太网卡的所有IPVLAN虚拟网卡的MAC地址都是一样的,因为宿主以太网卡根本不是用MAC地址来分流IPVLAN虚拟网卡的流量的。具体的流程如下图所示:
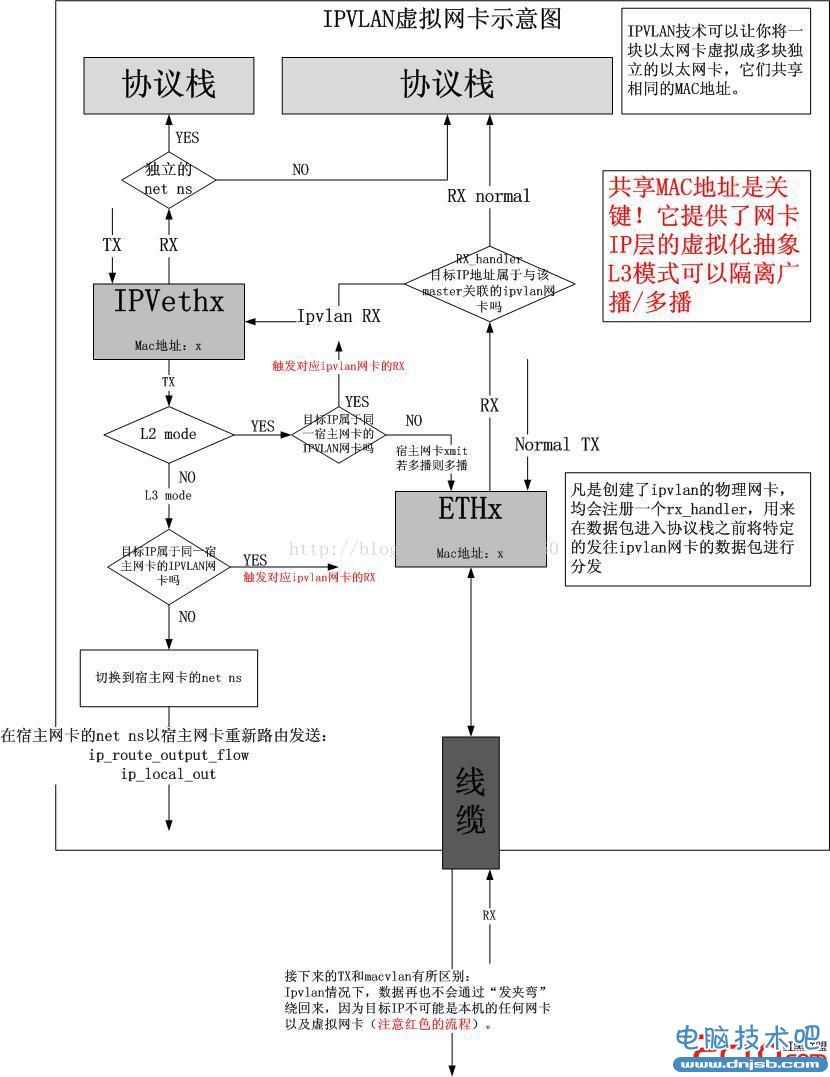
IPVLAN的创建命令如下:
ip link add link
将一个IPVLAN虚拟网卡放入一个独立的net namespace的方式和MACVLAN完全一样,但是它俩之间改如何作出选择呢?好在IPVLAN有Linux源码树上的Document,因此我就不多嘴了:
4.1 L2 mode: In this mode TX processing happens on the stack instance attached to the slave device and packets are switched and queued to the master device to send out. In this mode the slaves will RX/TX multicast and broadcast (if applicable) as well.
4.2 L3 mode: In this mode TX processing upto L3 happens on the stack instance attached to the slave device and packets are switched to the stack instance of the master device for the L2 processing and routing from that instance will be used before packets are queued on the outbound device. In this mode the slaves will not receive nor can send multicast / broadcast traffic.
5. What to choose (macvlan vs. ipvlan)? These two devices are very similar in many regards and the specific use case could very well define which device to choose. if one of the following situations defines your use case then you can choose to use ipvlan - (a) The Linux host that is connected to the external switch / router has policy configured that allows only one mac per port. (b) No of virtual devices created on a master exceed the mac capacity and puts the NIC in promiscous mode and degraded performance is a concern. (c) If the slave device is to be put into the hostile / untrusted network namespace where L2 on the slave could be changed / misused.
MACVTAP虚拟网卡技术
这是本文谈到的最后一种虚拟网卡。为什么会有这种虚拟网卡呢?我们还是从问题说起。如果一个用户态实现的虚拟机或者模拟器,它在运行OS的时候,怎么模拟网卡呢?或者说我们实现了一个用户态的协议栈,和内核协议栈完全独立,你可以把它们想象成两个net namespace,此时如何把物理网卡的流量路由到用户态呢?或者反过来,如何将用户态协议栈发出的数据路由到BOX外部呢?按照常规的想法,我们知道TAP网卡的endpoint是一个用户态可访问的字符设备,OpenVPN使用的就是它,很多轻量级用户态协议栈也有用到它,我们会给出下面的方案:
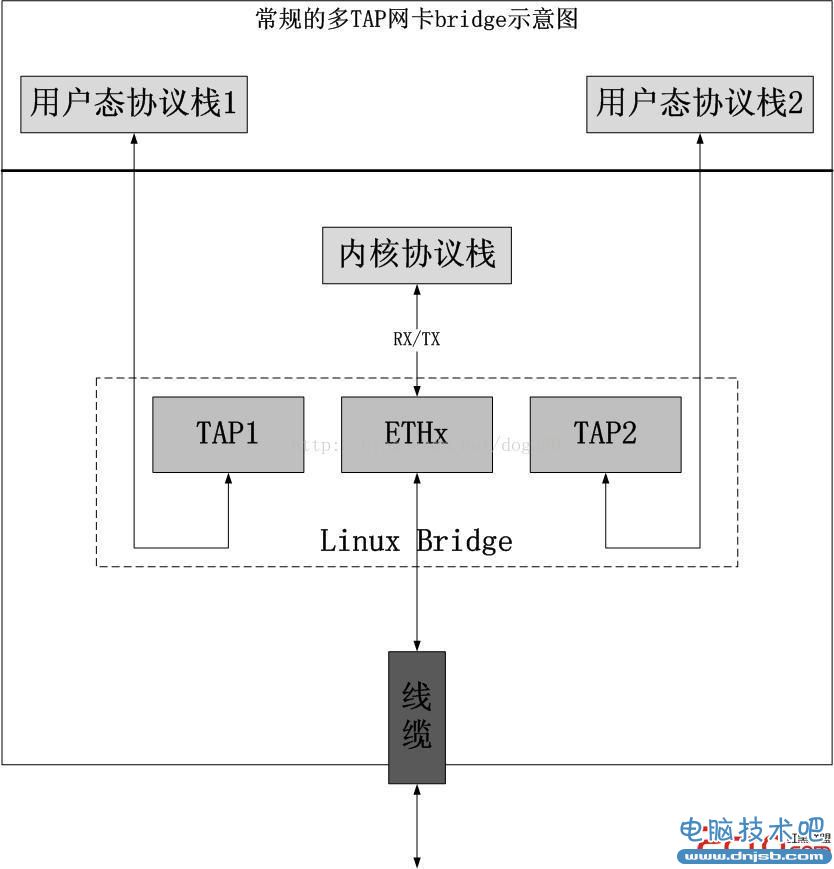
又要用到“万能的bridge”。这是多么的麻烦,这是多么的可悲。
正如MACVLAN替代VETH+Bridge一样,稍微该一下的MACVLAN也能替代TAP+Bridge,很简单,那就是将rx_handler实现修改一下,宿主以太网卡收到包之后,不交给MACVLAN的虚拟网卡上接口连接的协议栈,而是发到一个字符设备队列。很简单吧,这就是MACVTAP!
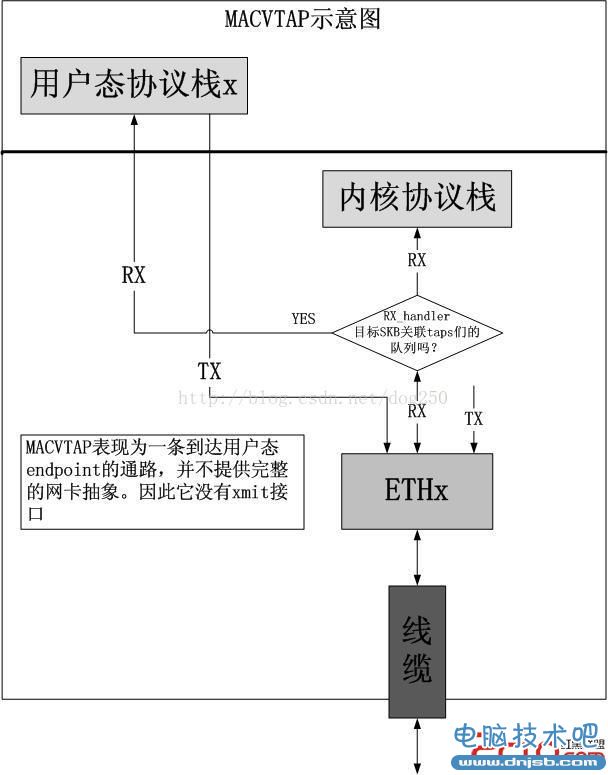
遗憾的多队列TUN/TAP虚拟网卡技术
这是老湿在2014年的时候做的,其实只是做了一些移植和修改工作。但是发现有了MACVTAP之后,我的这个版本瞬间就被爆了。遗憾!向之所欣,俯仰之间,已为陈迹。相关知识
-

linux一键安装web环境全攻略 在linux系统中怎么一键安装web环境方法
-

Linux网络基本网络配置方法介绍 如何配置Linux系统的网络方法
-
Linux下DNS服务器搭建详解 Linux下搭建DNS服务器和配置文件
-
对Linux进行详细的性能监控的方法 Linux 系统性能监控命令详解
-
linux系统root密码忘了怎么办 linux忘记root密码后找回密码的方法
-
Linux基本命令有哪些 Linux系统常用操作命令有哪些
-
Linux必学的网络操作命令 linux网络操作相关命令汇总
-

linux系统从入侵到提权的详细过程 linux入侵提权服务器方法技巧
-

linux系统怎么用命令切换用户登录 Linux切换用户的命令是什么
-
在linux中添加普通新用户登录 如何在Linux中添加一个新的用户
软件推荐
更多 >











-
1
 专为国人订制!Linux Deepin新版发布
专为国人订制!Linux Deepin新版发布2012-07-10
-
2
CentOS 6.3安装(详细图解教程)
-
3
Linux怎么查看网卡驱动?Linux下查看网卡的驱动程序
-
4
centos修改主机名命令
-
5
Ubuntu或UbuntuKyKin14.04Unity桌面风格与Gnome桌面风格的切换
-
6
FEDORA 17中设置TIGERVNC远程访问
-
7
StartOS 5.0相关介绍,新型的Linux系统!
-
8
解决vSphere Client登录linux版vCenter失败
-
9
LINUX最新提权 Exploits Linux Kernel <= 2.6.37
-
10
nginx在网站中的7层转发功能












