Twitter技术问题导致抓取和URL规范化问题
发布时间:2011-07-21 18:25:58作者:知识屋
6月27号Google工具条PR更新了一次,然后很多人注意到Twitter首页PR降为零。(Google首页也降到9,不过这不是重点。)7月19号Google居然又更新一次工具条PR。Google更新工具条PR值从一个月一次变到3个月一次,甚至半年一次,所以这次不到一个月就再次更新有点蹊跷。据目前透露的信息,这次更新PR貌似主要就是为了修正Twitter PR值的问题。
今天看到SEL上Vanessa Fox的一篇文章,解释了为什么Twitter的一些技术失误导致Google抓取、URL规范化、PR计算等一系列问题,很值得一读,所以大致翻译一下供读者参考。
为什么不是Google的错误,Google却这么上心,更新了PR呢?猜测原因有二,一是无论任何情况下Twitter首页PR为零,大家肯定是说Google有问题,而不是Twitter有问题,虽然其实确实是Twitter自己造成的。二是,在Google+推出的同时,Google与Twitter合作合同到期了,不能直接通过API抓数据了,这时候Twitter PR降为零,大家恐怕心里会嘀咕,这Google真是过了河马上就拆桥啊,Google不想被这个黑锅。
言归正传。
Google一位发言人回复SEL关于Twitter PR时说:
最近Twitter不断修改它们的robots.txt文件和HTTP头信息,玩得太起劲了,暂时造成Google算法处理Twitter时的URL规范化问题。现在规范化问题差不多解决了,所以我们更新了工具条PR以反映最新数据。Twitter在Google索引库里一直有很高PR,没有惩罚。
所以Vanessa Fox研究了一下Twitter到底有什么robots文件、服务器头信息、URL规范化问题。真是不看不知道,一看吓一跳。顺便提一下,Vanessa Fox是前Google员工,负责网管工具webmaster tools的。
预感这篇帖子会比较长,才刚开始就这么长了…
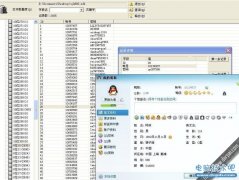
Vanessa Fox搜了一下自己名字“Vanessa Fox”,结果如下图:

有URL,但没标题,没说明,也就是其实没抓取,只是部分索引。
直接搜Vanessa Fox自己Twitter页面URL的结果是:

为什么出现了大写?URL最后面那个点(.)又是什么东东?到底怎么回事呢?
先来看看Twitter的robots.txt文件
twitter.com和www.twitter.com的robots.txt文件居然是不一样的。twitter.com/robots.txt是这样的:
#Google Search Engine Robot
User-agent: Googlebot
# Crawl-delay: 10 — Googlebot ignores crawl-delay ftl
Allow: /*?*_escaped_fragment_
Disallow: /*?
Disallow: /*/with_friends
#Yahoo! Search Engine Robot
User-Agent: Slurp
Crawl-delay: 1
Disallow: /*?
Disallow: /*/with_friends
#Microsoft Search Engine Robot
User-Agent: msnbot
Disallow: /*?
Disallow: /*/with_friends
# Every bot that might possibly read and respect this file.
User-agent: *
Disallow: /*?
Disallow: /*/with_friends
Disallow: /oauth
Disallow: /1/oauth
www.twitter.com/robots.txt是这样的:
User-agent: *
Disallow: /
也就是说:
某些情况下,带与不带www的两个版本内容可能是不一样的。
Twitter貌似为了规范和网址,禁止搜索引擎爬行www版本。
所以虽然www版本做了301转向到不带www的版本,但Twitter禁止搜索引擎抓www版本,所以搜索引擎蜘蛛看不到那个301啊。杯具啊。
连向Twitter的链接有的是链到www版本,有的是不带www的版本,既然www版本禁止爬行,看不到301,链接权重不能传递,浪费了。
所以在第一个抓图里看到返回的是带www的版本,可能原因是这个版本外链比较多,但Twitter禁止爬行,所以只是部分索引(也就是只有一些来自链接的数据,没有页面本身的内容)。
再来看看302转向
查一下twitter.com/vanessafox这个URL头信息,居然返回302转向到twitter.com/#!/vanessafox。为什么说“居然”呢?请参考301转向和302转向的区别。由于用的是302,权重没有转到twitter.com/#!/vanessafox
而www.twitter.com/vanessafox做了301到twitter.com/vanessafox,当然,原因www版本被屏蔽,链接权重也传递不过来。为什么不从www.twitter.com/vanessafox直接301到twitter.com/#!/vanessafox(这才是Twitter想要的规范化版本)呢?就算要做两次转向,也都要用301嘛,也不能屏蔽www版本嘛。
再来看看Twitter意图的AJAX抓取
Twitter想要的规范化URL是twitter.com/#!/vanessafox,其中的#表示Twitter希望搜索引擎抓取页面AJAX内容。(这里技术问题比较复杂,就不解释了,即将出版的《SEO艺术》有关于AJAX内容和#符号使用的解释,广告一下,呵呵)。
不过由于一系列复杂的转向,可能造成了问题:
Google爬行不带www带#!的URL(twitter.com/#!/vanessafox),然后被转向到twitter.com/_escaped_fragment_/vanessafox
然后Google又被301转向到带www不带#!的版本www.twitter.com/vanessafox
而用户访问时JS将用户又转回到带#!的版本
我读到这里时头脑已经比较凌乱了,总之,Twitter弄了一堆转向,目的是让twitter.com/vanessafox这个看着看着干干净净的版本出现在搜索结果中,但用户点击后又被转到twitter.com/#!/vanessafox。弄这么复杂干什么呢,越复杂越容易出错啊。
Rate Limiting又是什么呢
Twitter页面头信息里有一个rate limiting部分:
HTTP/1.1 200 OK
Date: Mon, 18 Jul 2011 20:48:44 GMT
Server: hi
Status: 200 OK
X-Transaction: 1311022124-32783-45463
X-RateLimit-Limit: 1000
这个limiting又limit(限制)了什么呢?Vanessa Fox不清楚,我就更不知道了,以前没见过这个参数。但limit这个词暗示着是限制了什么和速度有关的东西,要是指抓取速度就惨了。
URL中的大小写字母
最后,如第二个抓图显示的,URL中出现大小写字母,这些都是不同URL,又会造成网址规范化、PR/权重分散、复制内容等等问题。
终于到结尾了。总之,这种技术问题在很多大型网站是经常出现的,看似小问题,其实可能导致严重后果。
相关知识










软件推荐
更多 >











-
1电脑技术吧投稿系统开放!
2014-12-08
-
2
电脑技术吧官方网站移动客户发布了!
-
3
电脑技术吧QQ交流群
-
4
关于真假电脑技术吧的一些辨别!
-
5
2012年前半年电商排名:天猫第一 京东第二
-
6
元旦放假安排2015通知, 2015元旦放假安排日历详解!
-
7
MSDN我告诉你是什么网站?MSDN是微软官方的吗?
-
8
谈百度搜索显示网站ICO图标的一些心得!
-
9
腾讯QQ数据库泄露下载地址
-
10
支付宝新春红包怎么领取 2015支付宝钱包抢红包活动攻略