会java学c++难吗
发表时间:2022-03-23来源:网络
博主原本的语言是c++,好不容易上手了,刷算法题也熟练了一些,因为实习的缘故不得不开始接触java。下面总结一些c++和java的区别,有c++基础的人可以对照学习java。
一、从变量和数据类型上
1、数据类型
Java语言提供了八种基本类型,Java没有无符号整数。(无符号右移在Java中强制用三个右尖括号表示)
java和c++都支持布尔类型的数据,但是java实现true和false的方式与c++不同。在c++中,true是非零值,false是0.而java中,true和false是一个布尔表达式能得到的唯一的两个值,不会出现像c++一样把非0转为true的情况。
2、字符串
Java有内置类型String,而C++没有。C++的std::string是可变的,类似于Java的StringBuffer。(String,StringBuffer,StringBuilder三者异同)。java中的String一旦定义了就是个常量,不能被修改。比较字符串时,c++由于重写了“= =” 因此可用于比较,而java中不能用“==”,要用string的方法.equals()3、数组
(1)java定义数组的方式:
int[] array1=new int[100];//常用方式 int array2[];//数组维度无需确定相比较,c++的声明方式为:
int *array1=new int[100]; int array2[10];//数组维度必须是确定的(2)java可以进行数组拷贝,c++则是用指针或引用的形式实现这样的目的。java可以用如下方式:
int[] oddNum={1,3,5,7}; int[] copy=Arrays.copyOf(oddNum,oddNum.length);4、C++的整型随机器的位数而变化,但是Java不会。(C++的int在16位机器上16位,32位级以上为32位。long在32位及以下为32位,64位机器上为64位。)
5、Java中不存在指针和引用(这点真的很不习惯。。比如写两个数交换的字方法时,c++可以愉快的用引用传参)。Java的引用是功能弱化的指针,只能做“调用所指对象的方法”的操作。
6、java具有方法重载的能力,但不支持操作符重载
7、java新增了三个右移位运算符">>>",具有与“逻辑”右移位运算符类似的功能,可在最末尾插入0值。“>>"则在移位的同时插入符号位。
8、类型转换
c++中有时出现数据类型的隐含转换,这就涉及强制类型转换的问题。比如,c++中可以将一个浮点数赋予整型变量,去掉小数部分。java不支持c++中的自动强制类型转换,如果需要转换,必须由程序员进行显式的转换。如:
二、循环语句
写循环语句时,c++中可以直接用while(1), while(a),if(num)这种方式来做循环进行或终止的条件,而java中,括号里的表达式只能是布尔类型,如while(a!=10), while(b>1)这种写法。java中没有goto语句三、类机制
和c++相比,java所有东西必须置入一个类,即使是main函数public static void man(String[ ] args)也要放在类里面。java是完全面向对象的语言,不再支持c++所用的过程式的设计方法,所有的函数和变量必须是类的一部分。除了基本数据类型之外,其他的数据对java来说都是对象,包括数组。我们新建一个java文件时,这个文件名必须要与文件中定义的类名相同。一个java文件中必须要有至少一个public的类。java不存在全局函数或者全局数据,如果想获得全局的功能,可以将static方法和static数据置入一个类里面。而c++允许将函数和变量定义为全局的。此外,java中取消了c++结构中的联合,枚举这类东西,一切只有“类”(class)。与c++相比,java中不存在inline函数,没有virtual关键字,不提供多重继承机制。java支持构造函数,但是没有c++中的析构函数(java中增加了finalize()函数)。Java中的继承具有与C++相同的效果,但采用的语法不同。Java用extends关键字标志从一个基础类的继承,并用super关键字指出准备在基础类中调用的方法,它与我们当前所在的方法具有相同的名字(然而,Java中的super关键字只允许我们访问父类的方法——亦即分级结构的上一级四、包(package)
更好地组织类,Java 提供了包机制,用于区别类名的命名空间。 Java用包代替了命名空间。由于将所有东西都置入一个类,而且由于采用了一种名为“封装”的机制,它能针对类名进行类似于命名空间分解的操作,所以命名的问题不再进入我们的考虑之列。数据包也会在单独一个库名下收集库的组件。我们只需简单地“import”(导入)一个包,剩下的工作会由编译器自动完成。包的作用为:
把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。Java 使用包(package)这种机制是为了防止命名冲突,访问控制,提供搜索和定位类(class)、接口、枚举(enumerations)和注释(annotation)等。
包语句的语法格式为:
package pkg1[.pkg2[.pkg3…]];例如,一个Something.java 文件它的内容
package net.java.util; public class Something{ ... }那么它的路径应该是 net/java/util/Something.java 这样保存的。 package(包) 的作用是把不同的 java 程序分类保存,更方便的被其他 java 程序调用。
五、预处理
java不再有#define,#include等预处理程序的功能,而c++语言很重要的一个特点就是它的预处理程序。#define的功能在java中我们可以用定义常数的方式来取代,而#include在java中是不需要的。
六、自动内存管理
Java程序中所有的对象都是用new操作符建立在内存堆栈上,这个操作符类似于c++的new操作符。Java自动进行无用内存回收操作,不需要程序员进行删除。而c++中必须由程序员释放内存资源,增加了程序设计者的负担。Java中当一个对象不被再用到时,无用内存回收器将给它加上标签以示删除。Java里无用内存回收程序是以线程方式在后台运行的,利用空闲时间工作。
七、java接口
接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。
接口与类相似点:
一个接口可以有多个方法接口文件保存在 .java 结尾的文件中,文件名使用接口名接口的字节码文件保存在 .class 结尾的文件中接口相应的字节码文件必须在与包名称相匹配的目录结构中接口与类的区别:
接口不能用于实例化对象。接口没有构造方法。接口中所有的方法必须是抽象方法。接口不能包含成员变量,除了 static 和 final 变量。接口不是被类继承了,而是要被类实现。接口支持多继承。接口特性:
接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。
接口中可以含有变量,但是接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。
接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。
接口的声明语法格式如下:
interface 接口名称 [extends 其他的接口名] { // 声明变量 // 抽象方法 } /* 文件名 : NameOfInterface.java */ import java.lang.*; //引入包 public interface NameOfInterface { //任何类型 final, static 字段 //抽象方法 }实例:
/* 文件名 : Animal.java */ interface Animal { public void eat(); public void travel(); }八、数据结构的运用
c++中用STL容器来实现各类如堆栈,队列,数组等的运用。而java中使用collection接口实现的List,Map等。。。这一部分在算法题里应该会经常用到,说来话长。这里只能简单归纳总结一下。
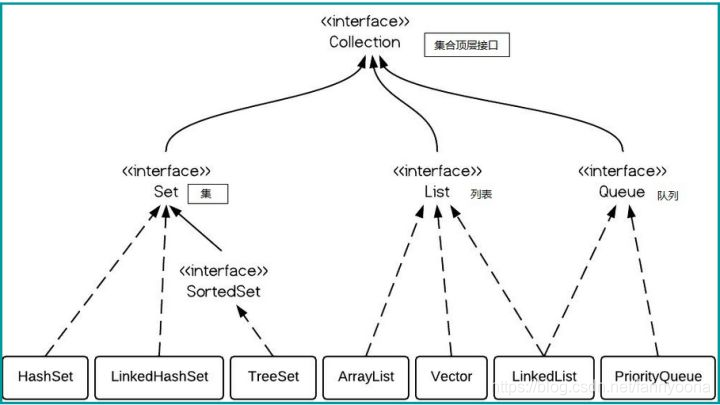
1、List
在List集合中允许出现重复的元素,所有元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的制定元素。并且List中元素有序,即,存入和取出顺序一致。
(1)ArrayList 就是动态数组,是Array的复杂版本,动态的增加和减少元素.当更多的元素加入到ArrayList中时,其大小将会动态地增长。它的元素可以通过get/set方法直接访问,因为ArrayList本质上是一个数组。
优点: 底层数据结构是数组Array,查询快,增删慢。
缺点: 线程不安全,效率高
(2)Vector 是比较早期会用的了,一般现在用得较少,和ArrayList类似, 底层数据结构是数组Array,查询快。增删慢。在于Vector是同步类(synchronized),线程安全的,因此,开销就比ArrayList要大,效率低一些。
(3)LinkedList 是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比。它还实现了 Queue 接口,该接口比List提供了更多的方法,包括 offer(),peek(),poll()等。
2、Set
(1)HashSet
HashSet中不能有相同的元素,可以有一个Null元素,存入的元素是无序的。HashSet底层数据结构是哈希表,哈希表就是存储唯一系列的表,而哈希值是由对象的hashCode()方法生成。(确保唯一性。当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等)
添加、删除操作时间复杂度都是O(1)。非线程安全。(2)LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,底层数据结构由哈希表和链表组成,链表保证了元素的有序即存储和取出一致,哈希表保证了元素的唯一性。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet中不能有相同元素,可以有一个Null元素,元素严格按照放入的顺序排列添加、删除操作时间复杂度都是O(1)非线程安全(3)TreeSet
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet是中不能有相同元素,不可以有Null元素,根据元素的自然顺序进行排序。底层的数据结构是红黑树(一种自平衡二叉查找树,保证元素的排序和唯一性)添加、删除操作时间复杂度都是O(log(n))非线程安全总结:三者都保证了元素的唯一性,如果无排序要求可以选用HashSet;如果想取出元素的顺序和放入元素的顺序相同,那么可以选用LinkedHashSet。如果想插入、删除立即排序或者按照一定规则排序可以选用TreeSet。
3、Map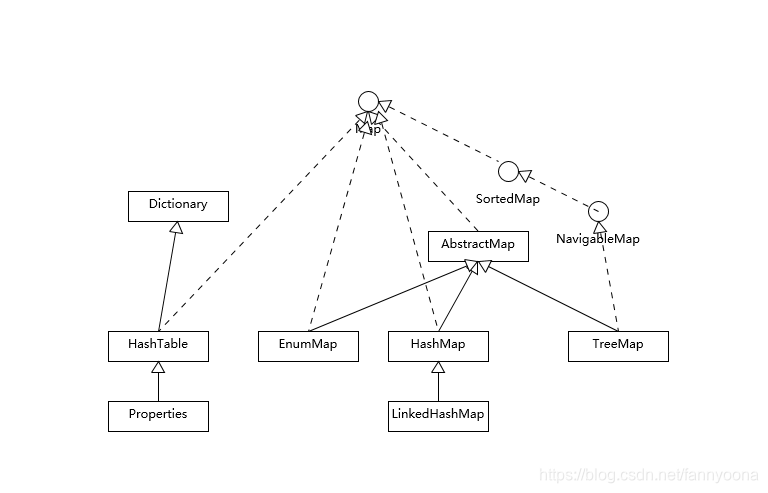
Hashtable、HashMap、TreeMap 都是最常见的一些 Map 实现,是以键值对的形式存储和操作数据的容器类型。
(1)HashMap(无序)
HashMap是一个最常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为null,不允许多条记录的值为null。HashMap是不安全的线程。它不支持线程的同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。(如果需要同步,可以用Collections.synchronizedMap(HashMap map)方法使HashMap具有同步的能力)一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
(2)Hashtable
Hashtable与HashMap类似,不同的是:它不允许记录的键或者值为空;是安全的线程支持线程的同步,即任一时刻只有一个线程能写Hashtable,然而,这也导致了Hashtable在写入时会比较慢。(3)LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的。在遍历的时候会比HashMap慢。有HashMap的全部特性。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
(4)TreeMap
TreeMap能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器。当用Iteraor遍历TreeMap时,得到的记录是排过序的。TreeMap的键和值都不能为空。HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap。
知识阅读










软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐




-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
5
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14














-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游