Java面试题简单归纳
发表时间:2022-03-25来源:网络
JavaSE
1、Object类自带哪些方法?
11个
2、对String类了解多少
1、String是java.lang包下一个类,是引用类型2、直接赋值的字符串, 都存在字符串常量池中3、String是一个类,也可以使用构造方式的形式创建对象
4、字符串本身不可变,因为是final类
5、字符串的比较需要使用equals()方法实现
6、String的底层是字节数组
3、String、StringBuffer、StringBuilder的区别
1、String是不可变的,StringBuffer和StringBuilder是可变的2、StringBuffer是线程安全的(用于多线程,操作大量数据)、StringBuilder是线程不安全的(用于单线程,操作大量数据),操作少量数据时用String
3、StringBuffer对象都有一定的缓冲区容量
4、性能:StringBuilder > StringBuffer > String
(String是final类,每次都需要新创建一个String对象,虽然StringBuilder和StringBuffer也是final类,但是它们是通过拼接的方式(append方法)来创建)
4、collection和collections的区别
Collection:是一个集合接口,继承它的接口主要有List、Set、:是一个针对集合类的一个帮助类。它包含有各种有关集合操作的静态方法。此类不能实例化,构造方法是私有的,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作5、Set里的元素是不能重复的,那么用什么方法来区分重复与否呢?
equals()、hashcode()6、从底层区分下ArrayList、LinkedList、HashMap的区别、初始大小及如何扩容
ArrayList与LinkedList的区别:ArrayList是数组,LinkedList是双向链表
查询的效率:ArrayList大于LinkedList
删除/增加元素的效率:LinkedList大于ArrayList的速率
总体效率:ArrayList大于LinkedListArrayList:
初始化大小是10
当新增的时候发现容量不够用了,就去扩容,扩容规则(JDK1.6以及之前扩容规则为:1.5倍+1 ; JDK1.7以及之后扩容规则为:1.5倍)LinkedList:
是一个双向链表,没有初始化大小,也没有扩容的机制,就是一直在前面或者后面新增HashMap:
初始化大小是 16 ,扩容因子默认0.75(可以指定初始化大小,和扩容因子)
扩容机制(当前大小 和 当前容量 的比例超过了 扩容因子,就会扩容,扩容后大小为1倍。例如:初始大小为 16 ,扩容因子 0.75 ,当容量为12的时候,比例已经是0.75 。触发扩容,扩容后的大小为 32)
7、HashMap、Hashtable的区别
HashMap:效率高、允许null key和null value、线程不同步且不安全(无synchronized)、父类是AbstractMap
默认初始容量为16,加载因子为0.75,扩容方法是resize(),扩容增量:原容量的1倍Hashtable:
效率低、不允许null key和null value、线程同步且安全(synchronized)、父类是Dictionary
默认初始容量为11,加载因子为0.75,扩容增量:原容量的1倍 +1
8、HashMap的底层
1、底层实现: 数组(位桶)+链表(哈希表)(JDK1.7)2、底层实现:数组+链表+红黑树(JDK1.8)在jdk1.8中,如果链表长度大于8且节点数组长度大于64的时候,就把链表下所有的节点转为红黑树3、基于散列表,并且用拉链法来解决哈希冲突的4、是无序的、效率高、key不允许重复、允许null key和null value、线程不同步且不安全(无synchronized)、父类是AbstractMap5、HashMap的初始容量为16,加载因子为0.75,扩容方法是resize(),扩容增量:原容量的1倍
9、HashMap、LinkedHashMap、ConcurrentHashMap的异同
1、LinedHashMap是HashMap的子类,底层都是哈希表,但ConcurrentHashMap的底层是(JDK1.8时是Node数组+链表+红黑树,JDK1.7时是sagment数组(重入锁:ReentrentLock) + HashEntry数组)2、LinkedHashMap拥有 HashMap 的所有特性,它比 HashMap多维护了一个双向链表,所以它的内存相比而言要比 HashMap 大,并且性能会差一些
3、LinedHashMap和HashMap允许null key和null value,且线程不安全,但ConcurrentHashMap不允许null key和null value、且线程安全
4、ConcurrentHashMap引入了分割(锁分离技术),使用的是分段锁,JDK1.7时锁的是每一个sagment数组元素
5、LinkedHashMap是有序的,但是HashMap是无序的
6、key都不允许重复
10、Java中HashMap的Key值要是为类对象,则该类需要满足什么条件?
必须重写 equals()和hashCode() 方法11、Comparable和Comparator接口是干什么的?列出它们的区别。
都是用来实现集合中元素的比较、排序的Comparable:在java.lang包下,只包含一个compareTo()方法,是在集合内部定义的方法实现的排序Comparator:在java.util包下,包含compare()方法,还包含了其他方法,是在集合外部定义的方法实现的排序12、什么是流?按照传输的单位,分成哪两种流?他们的父类叫什么?
流是指数据数组的序列,数据的传输字节流:InputStream、OutputStream字符流:Reader、Writer13、什么叫对象序列化,什么是反序列化,如何实现对象序列化
序列化:把对象转换为字节序列的过程反序列化:把字节序列恢复为对象的过程实现:必须实现Serializable接口(Serializable接口没有方法或字段,仅用于标识可串行化的语义)
使用对象流(ObjectInputStream、ObjectOutputStream)
14、开启线程的三种方式
1、继承Thread类,重写run方法,不然run方法为空2、实现Runnable接口,重写run方法
3、线程池通过Callable接口,重写call方法
15、进程、线程、协程之间的区别
进程与线程的比较:1、地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间
2、资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
3、线程是处理器调度的基本单位,但进程不是
4、二者均可并发执行,且都是同步机制
5、进程上下文的切换开销比较大,但相对比较稳定安全;线程上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据
6、一个线程可以多个协程,一个进程也可以单独拥有多个协程进程:是正在执行的一个程序,是资源分配的最小单位,操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源)线程:是进程中多个同时在执行的任务,是操作系统调度(CPU调度)执行的最小单位,有时被称为轻量级进程协程:是一种用户态的轻量级线程,协程的调度完全由用户控制,上下文的切换非常快,是异步机制
16、线程之间是如何通信的
Synchronized同步实现通信,属于“共享内存”式的通信,多个线程需要访问同一个共享变量,谁拿到了锁(获得了访问权限),谁就可以执行wait()、notify()、notifyAll(),线程的等待与唤醒实现通信管道通信:主要用来实现线程之间二进制数据的传播17、在Java中wait和sleep方法的不同
wait()会释放锁,而sleep()不会释放锁sleep()用时间指定来使它自动醒过来wait可以用notify()或notifyAll()直接唤起wait是Object类的方法,sleep是Thread类的静态方法sleep必须捕获异常,而wait不需要捕获异常18、谈谈ThreadLocal关键字
ThreadLocal被称为线程变量,ThreadLocal内部实现为每一个线程保存了一份副本变量。每一个线程都有一个map对象,map对象中存放了ThreadLocal对象的副本变量作用:使每个线程的资源隔离化,不会与其他线程造成冲突19、run()和start()方法区别
start():开启线程,真正实现了多线程,但是通过调用Thread类的start()方法来启动一个线程,这时此线程是处于就绪状态,并没有真正的运行,当分配到CPU时间片才进入运行状态。run():只是Thread类的一个普通方法20、什么是线程池,为什么要用线程池,说出几种常见的线程池
线程池:存储多个线程的容器线程池好处:1、重用存在的线程,减少对象创建、消亡的开销,提升性能
2、可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞
3、提供定时执行、定期执行、单线程、并发数控制等功能
4、限制系统中执行线程的数量常见线程池:
1、newCachedThreadPool():创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
2、newFixedThreadPool(int nThreads):创建一个定长线程池
3、newScheduledThreadPool(int corePoolSize):创建一个定长线程池 - 支持定时及周期性任务执行
4、newSingleThreadExecutor():创建一个单线程化的线程池
21、描述一下线程的生命周期(描述5个状态)
新建状态(New):当线程对象对创建后,即进入了新建状态。就绪状态(Runnable):当调用线程对象的start()方法,线程即进入就绪状态。运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态。死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。22、为什么会发生死锁,如何避免死锁
原因:同一个资源被多个进程争夺而造成的一种阻塞现象四个必要条件1、互斥条件:一个资源每次只能被一个进程使用。
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3、不可剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。避免方法
1、避免多次锁定(尽量避免同一个线程对多个锁进行锁定)
2、加锁顺序(保证多个线程它们以相同的顺序请求加锁)
3、加锁时限(线程获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
4、死锁检测(一种依靠算法(银行家算法)机制来实现的死锁预防机制,它主要是针对那些不可能实现按序加锁,也不能使用定时锁的场景的)
23、多线程中的锁有哪些种类,说下区别
公平锁/非公平锁公平锁:是指多个线程按照申请锁的顺序来获取锁
非公平锁:指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁可重入锁:又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁独享锁/共享锁
独享锁:指该锁一次只能被一个线程所持有
共享锁:指该锁可被多个线程所持有互斥锁/读写锁
互斥锁:只能有一个线程访问(ReentrantLock)
读写锁:只能有一个写者或多个读者,但不能同时既有读者又有写者(ReadWriteLock)乐观锁/悲观锁
不是指具体的什么类型的锁,而是指看待并发同步的角度
悲观锁:认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改
乐观锁:认为对于同一个数据的并发操作,是不会发生修改的分段锁:是一种锁的设计,并不是具体的一种锁偏向锁/轻量级锁/重量级锁:指锁的状态,并且是针对Synchronized自旋锁:指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁Synchronized:非公平,悲观,独享,互斥,可重入,重量级锁ReentrantLock:默认非公平但可实现公平的,悲观,独享,互斥,可重入,重量级锁ReentrantReadWriteLock:默认非公平但可实现公平的,悲观,写独享,读共享,可重入,重量级锁
24、Synchronized和Lock锁的区别
1、Lock是一个接口,而Synchronized是一个关键字2、Synchronized在发生异常时候会自动释放占有的锁,因此不会出现死锁;而lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生
3、Lock等待锁过程中可以用interrupt来中断等待,而Synchronized只能等待锁的释放,不能响应中断
4、Lock可以通过trylock来知道有没有获取锁,而Synchronized不能
5、Lock可以提高多个线程进行读操作的效率
6、Lock锁适合大量同步的代码的同步问题,Synchronized锁适合少量代码的同步问题
7、Synchronized使用Object对象本身的wait 、notify、notifyAll调度机制,而Lock可以使用Condition进行线程之间的调度
8、Synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
25、Synchronized有什么缺陷
1、保证了线程的安全,降低了速度和效率2、Synchronized只能等待锁的释放,不能响应中断
3、Synchronized只能锁一个对象,不能锁多个对象
4、Synchronized不能知道有没有获得锁
5、不能设置超时
26、并行与并发的异同
并行:当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,多CPU或者一个CPU多核。并发:在操作系统中,是指一个时间段中有多个进程都处于已启动运行到运行完毕之间,且这多个进程都是在同一个处理机上运行,互相抢占资源。并发是在一段时间内宏观上多个程序同时运行,并行是在某一时刻,真正有多个程序在运行。27、Java如何实现并发
1、synchronized关键字来保证一次只有一个线程在执行代码块2、Volatile关键字保证任何线程在读取Volatile修饰的变量的时候,读取的都是这个变量的最新数据
3、继承Thread、实现Runnable、Thread pools实现多线程
28、什么是深克隆浅克隆?描述两个的区别
深克隆、浅克隆的划分完全是根据是否克隆引用属性来说的。对于基本类型变量,克隆后数值大小相同即可,但对于引用数据类型,深克隆会复制引用指向的对象,而浅克隆只会克隆引用。29、什么是双亲委派模型?
加载一个类的时候, 会先由引导类加载器和扩展类加载器 来搜索有没有对应的类
如果有, 那么就加载完成,
如果没有, 会继续使用应用类加载器来完成搜索和加载工作
如果三个类加载器都找不到对应的类, 那么就会抛出ClassNotFoundException
问:自己定义一个java.lang.String类, 能不能使用?
不能
30、什么是类加载?类加载的过程是怎样的?
类加载:将.java文件编码成.class文件,jvm虚拟机启动时,通过一个.class对象来调用它,并为之生成的java.lang.Class对象类加载过程加载:将字节码数据读取到JVM中,并转化为Class对象
链接:把原始的类信息转入JVM运行的过程中(验证、准备、解析)
初始化:执行类初始化的代码逻辑,包括静态字段和静态代码块
31、Java有没有内存泄漏
实际情况存在内存泄漏,虽然Java因为有垃圾回收机制(GC)理论上不会存在内存泄漏问题,但是在实际开发中,可能会存在无用但可达的对象,这些对象不能被GC回收也会发生内存泄漏32、Runnable和Callable的区别
1、Runnable提供run方法,无法通过throws抛出异常,所有CheckedException必须在run方法内部处理。Callable提供call方法,可以直接抛出Exception异常。2、Runnable的run方法无返回值,Callable的call方法提供返回值用来表示任务运行的结果
3、Runnable可以作为Thread构造器的参数,通过开启新的线程来执行,也可以通过线程池来执行,而Callable只能通过线程池执行
33、重定向和转发的区别,对应的方法是什么?
重定向:redirect,告诉浏览器请求另一个地址,地址栏的url改变,请求2次,不带有参数转发:forward,请求不中断,转发到另一个资源,请求另一个地址后再把返回内容返回给客户端,地址栏url不改变,请求1次,带有参数34、为什么String/Integer这样的包装类适合作为Key值
hashMap的存储过程:需要同时重写该类的hashCode方法和equals方法
在插入元素的时候是先算出对象的hashCode,hashCode相等的话,那么说明该对象是存储在同一个位置上,再调用equals方法,如果两个key相同,则覆盖元素,如果两个key不相同,则说明这个hashCode只是碰巧相同,这时候会出现hash冲突,则将新增的元素放在链表最后
35、重载和重写的区别?
重载:在同一个类当中有多个名称相同方法,但各个相同方法的参数列表不同(无关返回值类型)重写:发生在不同的类当中,并且两者要有继承关系,重写是方法名字和参数的列表是要完全一致的,访问权限大于等于父类,抛出的异常和返回值类型(若是引用类型)小于等于父类,重写的意义在于父类的方法已经不能满足时,子类重写为自己需要的36、HashSet原理
是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75的HashMap无序,不允许重复,允许有null值37、线程同步的方式
1、wait():使一个线程处于等待状态2、sleep():使一个正在运行的线程处于睡眠状态
3、notify():唤醒一个处于等待状态的线程
4、notityAll ():唤醒所有处于等待状态的线程
38、TreeSet用什么方法来区分元素是否重复
实现Comparable接口,用compareTo方法数据库&JDBC
1、数据库三范式是什么
1NF:数据库表的每一列都具有原子性,是不可分割的2NF:在1NF基础上消除部分函数依赖3NF:在2NF基础上消除传递依赖2、SQL分为哪几个大类
DDL(数据定义语言) - 和数据库以及数据表的 CRUD(增删改查) 操作DML(数据操纵语言) - 和表中的记录相关的 CRUD 操作DQL(数据查询语言) - select 记录DCL(数据控制语言) - 数据库服务器的操作权限、用户等相关的3、SQL约束有哪几种
主键约束(primary key) - 特点:非空且唯一非空约束(not null) - 特点:不能为空唯一约束(unique) - 特点:唯一,不能重复外键约束(foreign key) - 特点:保证一个表中的数据匹配另一个表中的值check约束 - 特点:保证列中的值符合指定的条件default约束 - 特点:规定没有给列赋值时的默认值4、having、where、groupby的执行顺序
where -> groupby -> having5、什么是事务,事务有哪四个特性(详细解释,其中由隔离性触发的问题有哪些)
事务:业务层面上不可分割的最小单位,是数据库操作的最小单元事务四个特性原子性:事务的各步操作是不可分割的
一致性:当事务完成时,数据必须处于一致状态
隔离性:事务与事务之间不应该相互影响,执⾏时保持隔离的状态
持久性:事务完成后,它对数据库的修改是永久保存的隔离性触发的问题
脏读:一个事务读取到了另一个事务未提交的数据
幻读:一个事务两次读取,数据的数量、个数不同(增、删)
不可重复读:一个事务两次读取,数据内容不同(改)
6、并发下事务会产生哪些问题,可用对应的哪个事务隔离级别来解决
读未提交:read uncommitted(都不能解决)读已提交:read committed(只能解决脏读)(Oracle)可重复读:repeatable read(能解决脏读和不可重复读)(MySqL)串行化:serializable(都可解决)(隔离级别最高,性能最差,安全性最高)7、Oracle和MySQL的区别(包括默认事务隔离级别)
1、MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交2、MySQL有limit就可以实现分页,而Oracle则是需要用到伪列ROWNUM和嵌套查询
3、MySQL是可重复读的隔离级别,而Oracle是读已提交的隔离级别
4、MySQL在innodb存储引擎的行级锁的情况下才可支持事务,而Oracle则完全支持事务
5、MySQL是在数据库更新或者重启,则会丢失数据,Oracle把提交的数据保持到了磁盘上,可以随时恢复
6、Oracle比MySQL对并发性的支持要好很多
7、MySQL是轻量型数据库(免费),Oracle是重量型数据库(收费)
8、什么是事务的传播行为,为什么要有传播行为
事务传播行为:指当一个业务方法被另一个业务方法调用时,业务中的事务方法应该如何进行好处:保证了数据库数据的安全,也保证了事务之间的交互安全REQUIRED:如果当前没有事务,就新建⼀个事务,如果已经存在⼀个事务中,加入到这个事务中。⼀般的选择(默认值)SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行(没有事务)9、drop table、delete from table和truncate的区别
drop table:删除表delete from table:删除表中的数据(挨个删除)truncate:删除表中的数据(删除表,重新建表)10、列举几种表连接方式,有什么区别
内连接:只显示两个表匹配的行与列隐式内连接:看不到 JOIN 关键字,条件使用WHERE 指定
显示内连接:使用INNER JOIN … ON 语句,可以省略 INNER外连接
左外连接:使用LEFT OUTER JOIN … ON,OUTER 可以省略,在内连接的基础上保证证左表的数据全部显示
右外连接:使用 RIGHT OUTER JOIN … ON,OUTER 可以省略,在内连接的基础上保证右表的数据全部显示
11、什么是视图,以及视图的优缺点
视图:通过查询建立得到一张临时表,然后保存下来优点1、简化了操作,把经常使用的数据定义为视图
2、安全性,用户只能查询和修改能看到的数据
3、逻辑上的独立性,屏蔽了真实表的结构带来的影响缺点:性能差、修改受限制
12、什么是索引,索引的分类,索引有哪些优缺点,建立索引有哪些原则
索引:可以加快从表或视图中查询数据的速度分类普通索引:仅加速查询
唯一索引:加速查询 + 数据唯一
主键索引:加速查询 + 数据唯一且不能为空
组合索引:多列值组成一个索引,专门用于组合搜索
全文索引:对整个表的数据内容进行搜索优点
1、大大加快数据的查询速度
2、创建唯一性索引,保证数据库表中每一行数据的唯一性
3、可以加速表和表之间直接的连接缺点
1、索引需要占物理空间
2、当对表中的数据进行增、删、改时,索引也要动态的维护,降低了数据的维护速度建立索引规则
1、经常出现在where、distinct、表连接条件的列,可以添加索引
2、数据量很大的表推荐添加索引,数据量小的表不推荐添加索引
3、经常需要DML操作的表,不建议添加索引
13、如何优化数据库
1、选取最适用的字段属性2、使用连接来代替子查询
3、使用事务、索引、外键
4、避免小心死锁
5、优化查询语句
14、描述JDBC连接数据库的步骤
1、加载驱动2、获得连接对象 Connection
3、获得操作数据库对象 Statement
4、执行Sql语句
5、处理 SQL 执行的结果集
6、释放资源
15、什么是SQL注入,怎样防止
SQL注入:通过字符串的拼接, 将整个SQL语句的语义结构改变了, 从而达到一定目的(不安全的语法, 一定要避免)防止:PreparedStatement 可以有效防止SQL注入(预编译)16、什么是数据库连接池,实现原理以及优势
数据库连接池:存储多个数据库连接的一个容器原理:在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用优势1、连接使用完成后, 可以将连接归还给连接池,让连接重复使用
2、在使用数据库连接的时候, 就可以快速获得连接对象
3、统一的连接管理,避免数据库连接泄漏
17、什么是存储过程、什么是函数、怎样创建存储过程和函数
存储过程:是在大型数据库系统中,一组为了完成特定功能的SQL语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它(call procedure_name(params);)。函数:是指一段可以直接被另一段程序或代码引用的程序或代码。也叫做子程序、(OOP中)方法。是由一个或多个 SQL 语句组成的子程序,可用于封装代码以便重新使用(select function_name(params);)。创建存储过程:使用create procedure语句创建函数:使用create function语句存储过程和函数的区别在于存函数是必须有返回值的,而存储过程并没有。所以可以说函数是一个有返回值的存储过程,而存储过程是一个没有返回值的函数。18、什么是触发器,触发器有哪些作用
触发器:是一种特殊的存储过程,是由事件来触发某个操作。这些事件包括insert语句、update语句和delete语句。当数据库系统执行这些事件时,会激活促发其执行相应的操作。触发器作用1、触发器可通过数据库中的相关表实现级联更改
2、触发器可以强制为更复杂的约束
3、触发器可以强制执行业务规则
4、触发器可以评估数据修改前后的表状态,并根据其差异采取对策
19、Redis
Redis是一种非关系型数据库1、Redis支持丰富的数据类型,比如String/List/Hash/Set/Sorted set2、Redis支持master-slave(主-从)模式应用。(主从模式既可以提高计算效率,又实现了信息隐藏)
3、Redis支持数据持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Web前端&网络协议
1、Ajax请求有几种返回值
xml、html、script、JSON、text2、Ajax有几部分组成,核心是什么
组成
1、Javascript:是通用的脚本语言,用来嵌入在某些应用中。而Ajax应用程序就是使用JavaScript来编写的。
2、CSS:为Web页面元素提供了可视化样式的定义方法。Ajax应用中,用户界面的样式可以通过CSS独立修改。
3、DOM(文档对象模型):通过JavaScript修改DOM,Ajax应用程序可以在运用时改变用户界面,或者局部更新页面中的某个节点。
4、XMLHttpRequest对象:允许Web程序员从Web服务器以后台的方式来获取数据。
核心:XmlHttpRequest对象,是一种支持异步请求的技术
3、什么是JSON,JSON的优缺点
JSON:是JavaScript对象表示法,是存储和交换文本信息的语法
优点
1、数据格式比较简单,易于读写
2、易于解析这种语言
3、支持多种语言,便于服务器端的解析
4、广泛的支持浏览器与操作系统的兼容性
缺点
1、没有错误处理机制
2、安全性低
3、支持工具有限
4、web中常用http状态码以及含义
200 - 正常返回响应404 - 资源未找到, 路径错误
500 - 代码出现异常
405 - 服务方法出错 service, doGet, doPost
304 - 访问缓存,请求资源没有改变
302 - 重定向
5、Http与Https的区别
传输信息安全性不同http协议:是超文本传输协议,信息是明文传输
https协议:是具有安全性的ssl加密传输协议,为浏览器和服务器之间的通信加密连接方式不同
http协议:http的连接很简单,是无状态的
https协议:是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议端口不同
http协议:端口是80。
https协议:端口是443证书申请方式不同
http协议:免费申请。
https协议:需要到CA申请证书
6、什么是Http协议无状态协议?怎么解决Http协议与状态协议?
无状态协议:对于事物处理没有记忆能力,也就是说,当客户端第一次向服务器发送http请求完成之后,再一次向服务器发送http请求,服务器并不知道该客户端是一个老用户解决1、携带Cookie,Cookie相当于是一个通行证,当客户端第一次向服务端发送http请求时,服务端向客户端返回一个cookie,当客户端再次发送http请求时携带该cookie,于是服务端便知道该客户端是一个老用户了
2、通过Session会话保存
7、常用的Http方法有哪些
GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器POST:用于传输数据给服务器,主要功能与GET方法类似,但一般推荐使用POST方式PUT: 传输数据,报文主体中包含文件内容,保存到对应URI位置HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件OPTIONS:查询相应URI支持的HTTP方法8、TCP和UDP的区别
TCP(传输控制协议):面向连接,提供可靠的服务,传输效率相对较低,TCP连接只能是点到点、一对一,面向字节流UDP(用户数据报协议):无连接,不可靠性,传输效率高,UDP连接支持一对一,一对多,多对一和多对多的交互通信,面向报文9、什么是TCP三次握手,什么是四次挥手
三次握手第一次握手:客户端想要连接,创建传输控制块TCB,状态变为主动打开,客户端进入SYN-SENT(同步已发送)状态
第二次握手:TCP服务器收到连接请求报文,如果同意连接则发送确认报文,服务器也进 入SYN-RCVD (同步已收到) 状态
第三次握手: 客户端收到确认后还要再向服务器发送确认报文,客户端和服务器都进入ESTABLISHED(已建立)状态四次挥手
第一次挥手:客户端发送请求释放连接报文给服务器
第二次挥手:服务器接收到客户端发来的请求释放报文以后,发送确认报文告诉客户端我收到了请求
第三次挥手:服务器所有的数据都发送完了,于是向客户端发送连接释放报文
第四次挥手:客户端接收到了服务器发送的连接释放报文,发出确认,客户端撤销相应的TCB后,客户端才进入关闭状态,而服务器在接收到确认报文的时候就立马关闭了
10、简述从输入网址到获得页面的过程
1、DNS(域名系统)域名解析2、根据IP地址,找到对应的服务器,发起TCP的三次握手
3、建立TCP连接后发起HTTP请求
4、服务器响应HTTP请求,浏览器得到相应的HTML文件代码
5、浏览器解析HTML代码,并请求HTML代码中的资源
6、浏览器对页面进行渲染呈现给用户
7、服务器关闭TCP连接
Servlet&JSP&Tomcat
1、浏览器输入URL到页面加载经历了哪些过程?
1、DNS域名解析2、根据IP地址,找到对应的服务器,发起TCP的三次握手
3、建立TCP连接后发起HTTP请求
4、服务器响应HTTP请求,浏览器得到相应的HTML文件代码
5、浏览器解析HTML代码,并请求HTML代码中的资源
6、浏览器对页面进行渲染呈现给用户
7、服务器关闭TCP连接
2、简述Servlet生命周期
默认第一次接收到请求时创建,服务器关闭时销毁Servlet四种状态(1)加载和实例化
当Servlet容器启动或客户端发送一个请求时,Servlet容器会查找内存中是否存在该Servlet实例,若存在,则直接读取该实例响应请求;如果不存在,就创建一个Servlet实例。
(2)初始化
实例化后,Servlet容器将调用Servlet的init()方法进行初始化(一些准备工作或资源预加载工作)。
(3)处理请求服务
初始化后,Servlet处于能响应请求的就绪状态。当接收到客户端请求时,调用service()的方法处理客户端请求,HttpServlet的service()方法会根据不同的请求 转调不同的doXxx()方法。
(4)销毁
当Servlet容器或服务器关闭时,Servlet实例也随时销毁。其间,Servlet容器会调用Servlet的destroy()方法去判断该Servlet是否应当被释放(或回收资源)。
3、forward和redirect的区别
forward:转发1、客户端只发送了一次请求
2、浏览器地址栏不会发生改变
3、使用request域来分享数据
4、转发的性能要优于重定向redirect:重定向
1、客户端发送了两次请求
2、浏览器地址栏会发生改变, 变成第二次请求地址
3、不能使用request域来分享数据
4、什么是Cookie?Session和Cookie有什么区别?
Cookie:是客户端技术,不安全,但可以减轻服务器压力,客户端可以清除Cookie,保存的是字符串Session:是服务器技术,安全,但服务器压力较大,保存的是对象,Session默认需要借助cookie才能正常工作,可以作为Session域对象(生存周期为一次会话)5、什么是监听器,有什么作用
监听器:对内置对象的状态或者属性变化进行监听并且做出反应的特殊servlet作用1、统计在线人数,利用HttpSessionListener
2、加载初始化信息,利用 ServletContextListener
3、统计网站访问量
4、实现访问监控
6、什么是过滤器,有什么作用
过滤器:进行过滤,实现代码的定向执行和预处理作用1、自动登录
2、解决乱码
3、权限判断
7、JSP静态包含和动态包含的区别
语法不同静态包含: 是指令元素
动态包含: 是行为元素编译成java文件的数目不同
静态包含:整体编译,最终编译为一个java文件
动态包含:分别编译,最终编程成多个java文件执行时间不同
静态包含:发生在 JSP---->java文件阶段
动态包含发生在:执行class文件阶段静态包含在两个文件中不能有相同的变量,动态包含允许无论是动态包含还是静态包含,其request对象都是相同的,也就是同一个request对象
8、JSP的内置对象和作用
out:用来传送回应的输出request:用户端请求,此请求会包含来自GET/POST请求的参数response:网页传回客户端的回应config:服务器配置,可以获得初始化参数session:与请求有关的会话期,用来保存用户的信息application:servlet 正在执行的内容,所有用户共享的信息page:JSP网页本身,指当前页面转换后的Servlet类的实例pageContext:JSP的页面容器,网页的属性是在这里管理,可以获取其他8个内置对象exception:表示JSP页面所发生的异常,在错误页中才起作用9、Servlet和JSP的联系和区别
联系:JSP是Servlet技术的扩展,本质上就是Servlet的简易方式区别Servlet:应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来,主要用于控制逻辑
JSP:是Java和HTML组合成一个扩展名为.jsp的文件,用于页面,侧重于视图
10、get和post的区别
get:参数位置在url中,参数长度有限制,只能进行url编码,参数的数据类型只接受ASCII字符,不重复提交,回退无害,参数暴露,不安全,可以缓存,可以收藏为书签,参数保留在浏览器历史中,请求包个数1个(http header+data)post:参数位置在request body中,参数长度无限制,支持多种编码方式,参数的数据类型没有限制,重复提交,回退有害,安全性高,不可以缓存,不可收藏为书签,不保留在浏览器历史,请求包个数2个(先http header,再data)本质上都是TCP链接,最大的区别是,get产生一个TCP数据包,post产生两个TCP数据包(但是在火狐浏览器也只产生一个TCP数据包)11、web.xml的作用
web.xml主要用来配置,可以方便的开发web工程web.xml主要用来配置Filter/Listener/Servlet等web.xml不是必须的,一个web工程可以没有web.xml文件12、Tomcat的缺省端口是多少,怎么修改
Tomcat缺省端口是8080修改1、找到Tomcat目录下的conf文件夹
2、进入conf文件夹里面找到server.xml文件
3、打开server.xml文件
4、在server.xml文件里面找到下列信息
< Connector port=”8080″
maxThreads=”150″ minSpareThreads=”25″ maxSpareThreads=”75″
enableLookups=”false” redirectPort=”8443″ acceptCount=”100″
connectionTimeout=”20000″ disableUploadTimeout=”true” />
5、把port=”8080″改成port=”8888″,并且保存
6、启动Tomcat,并且在IE浏览器里面的地址栏输入http://localhost:8888/
13、Tomcat有哪几种部署方式
直接将hello文件夹拷贝到 webapps 中,重启服务器将hello文件打包成war文件,将hello.war文件复制到 webapps 中,服务器正在运行,会自动解压war文件修改conf/server.xml文件,重启服务器 在conf/Catalina/localhost/创建hello.xml
14、 JSP 的常用指令
:用来在JSP 页面包含静态资源:用来指定JSP 页面标签类型:用来指定页面相关属性15、解释一下什么是servlet
Servlet:是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层使用 Servlet,可以收集网页表单的用户输入,呈现来自数据库或者其他源的记录,还可以动态创建网页16、 Ajax的实现流程是怎样的?
1、创建一个异步调用对象(XMLHttpRequest)2、创建一个新的请求,并指定该请求的方法、URL及响应信息类型
3、设置响应请求变化的方法
4、发送请求
5、获取异步调用返回的数据
6、实现局部刷新
SSM&SSH
1、Spring在SSM中起什么作用?
Spring框架将各层内容进行整合,并且提供IOC(反转控制,实现bean对象的创建、依赖注入)和AOP(面向切面编程,实现事务管理和方法增强)的操作是轻量级框架,作为bean工厂,用来管理bean的生命周期和框架整合2、Spring的事务?
基于SpringAOP技术声明式事务管理:将业务代码和事务管理分离,用注解和xml配置来管理事务配置Spring事务的步骤(基于xml)1、注册Spring事务管理的通知类(注入dataSource依赖)
2、配置Spring事务管理的属性(隔离级别、传播行为、只读性)
3、配置切入点
4、Spring事务管理通知的织入
3、IOC在项目中的作用?
降低系统代码的耦合性,解决对象之间的依赖问题,通过配置文件或注解关联起来进行依赖注入4、Spring的配置文件中的内容?
主要实现bean对象的创建、依赖关系的注入、bean对象的分发等功能5、Spring下的注解?
将实体类注册到Spring容器@Component:用于创建对象,作用于类
@Controller: 一般用于表现层的注解
@Service: 一般用于业务层的注解
@Repository: 一般用于持久层的注解
@Bean:用于把当前方法的返回对象作为bean对象存入spring容器用于注入数据
@Autowired:自动注入
@:在自动注入的基础之上,再按照 bean 的 id 注入
@Resource:直接按照 Bean 的 id 注入
@Value:注入基本数据类型和 String 类型数据的属性改变作用范围的
@singleton:单例的
@prototype:多例的和生命周期相关的
@PostConstruct:用于指定初始化方法
@PreDestroy:用于指定销毁方法配置相关
@Configuration:用于指定当前类是一个 spring 配置类
@ComponentScan:用于指定 spring 在初始化容器时要扫描的包
@Import:用于导入其他的配置类
@PropertySource:用于导入properties文件Spring 整合 Junit
@RunWith(SpringJUnit4ClassRunner.class):使用@RunWith 注解替换原有运行器
@ContextConfiguration(locations= {“classpath:bean.xml”}):用于指定配置文件的位置
6、Spring DI的四种方式?
1、构造器注入(默认无参构造器注入)2、set方法注入
3、p命名空间注入
4、spel(Spring)表达式注入
7、Spring主要使用了什么模式?
工厂模式:每个Bean对象的创建通过的方法单例模式:默认的每个Bean对象的作用域都是单例代理模式:SpringAOP的实现通过代理模式8、IOC,AOP的实现原理?
IOC(反转控制,实现bean对象创建、依赖注入):是基于Java的反射机制以及工厂模式实现的AOP(面向切面编程,实现事务的管理和方法增强):主要是使用动态代理实现的9、SpringMVC的控制器是不是单例模式,如果是,有什么问题,怎么解决?
默认是单例模式,所以在多线程访问的时候会有线程安全问题解决方案:把控制器类的scope注解参数设置成是多例的作用:1、提高性能(不需要每次请求都创建对象)
2、不需要多例(不需要在控制器类中定义成员变量)
10、SpringMVC中控制器的注解?
@Re:设置请求地址@ResponseBody:设置是返回具体数据类型而非跳转@Controller: 一般用于表现层注册对象的注解11、@Re注解用在类上的作用?
Re是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径12、前台多个参数,这些参数都是一个对象,如何快速得到对象?
直接在方法中声明这个对象,SpringMVC就自动会把属性赋值到这个对象里面13、SpringMVC中函数的返回值?
String(转发到 .jsp 页面)、void(重定向、转发)、ModelAndView(转发到 .jsp 页面)、JSON14、SpringMVC中的转发和重定向?
转发1、使用request关键字(也可以省略)
2、使用request对象
3、使用ModelAndView对象return "forward:/WEB-INF/pages/success.jsp"; request.getRe("/WEB-INF/pages/success.jsp").forward(request, response); modelAndView.setViewName("forward:/WEB-INF/pages/success.jsp"); 重定向
1、使用redirect关键字(不能省略)
2、使用response对象
3、使用ModelAndView对象return "redirect:/error.jsp"; response.sendRedirect(request.getContextPath() + "/error.jsp"); modelAndView.setViewName("redirect:/error.jsp");
15、SpringMVC和Ajax之间的相互调用?
通过JackSon框架把java里面对象直接转换成js可识别的json对象具体步骤如下:1、导入JackSon.jar
2、返回JSON对象方法的前面需要加上注解@ResponseBody
16、SpringMVC的工作流程图?
前端控制器、处理器映射器、处理器、处理器适配器、视图解析器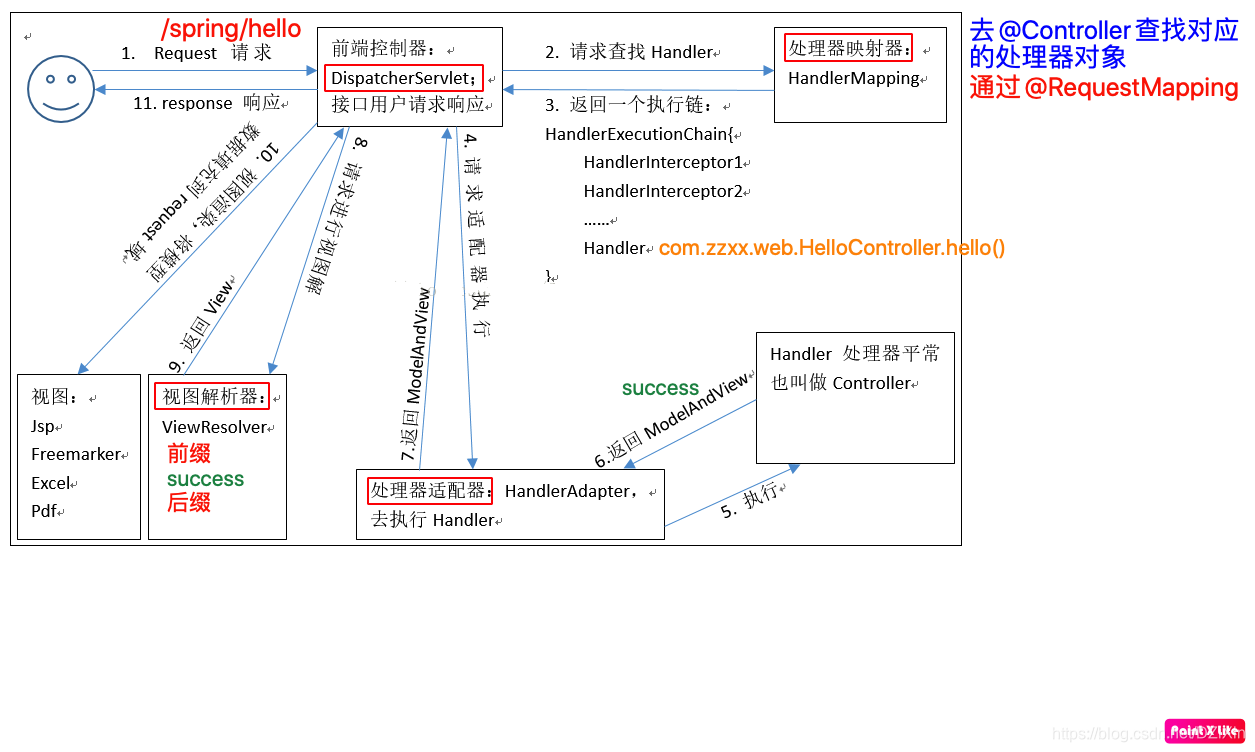
17、Struts2 和 SpringMVC 的区别?
入口不同SpringMVC的入口是servlet,而Struts2是filter开发方式不同
Struts2:基于类开发,传递参数通过类的属性,只能设置为多例
SpringMVC:基于方法开发(一个url对应一个方法),请求参数传递到方法形参,可以为单例也可以为多例(建议单例)SpringMVC的开发效率和性能要高于Struts2
18、Struts2 的框架原理?
https://blog.csdn.net/u011958281/article/details/7468565919、MyBatis 和 Hibernate 比的优劣势?
Hibernate和MyBatis都支持JDBC和事务处理Mybatis1、MyBatis可以进行更为细致的SQL优化,可以减少查询字段
2、MyBatis容易掌握,而Hibernate门槛较高Hibernate
1、Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射
2、Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便
3、Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL
4、Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳
20、什么是MyBatis的接口绑定,有什么好处?
接口绑定:在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以两种绑定实现方式1、通过注解绑定,就是在接口的方法上面加上 @Select、@Update等注解,里面包含Sql语句来绑定
2、通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名好处:调用方法明确,可以有更加灵活的选择和设置,效率更高
21、什么情况用注解,什么情况用xml绑定?
当Sql语句比较简单时候,用注解绑定当SQL语句比较复杂时候,用xml绑定,一般用xml绑定的比较多22、MyBatis的核心处理类叫什么?
核心处理类是S
Ser:每一个MyBatis的应用程序的入口Ser,它的作用是通过XML配置文件创建Configuration对象,然后通过build方法创建S对象
S:主要功能是创建S对象
S:完成一次数据库的访问和结果的映射,来获得接口的代理对象,它类似于数据库的session概念,由于不是线程安全的,所以S对象的作用域需限制方法内
Executor:在创建Configuration对象的时候创建,并且缓存在Configuration对象里,主要功能是调用StatementHandler访问数据库,并将查询结果存入缓存中(如果配置了缓存的话)
StatementHandler:真正访问数据库的地方,并调用ResultSetHandler处理查询结果
ResultSetHandler:处理查询结果
23、查询表名和返回实体Bean对象不一致,如何处理?
1、通过sql语句的字段起别名,别名和实体中的对象属性一致2、使用reslutMap对象来映射字段名和实体类属性名的一一对应关系24、MyBatis的好处?
1、简单易学,容易上手(相比于Hibernate) 基于SQL编程2、消除了JDBC大量冗余的代码,不需要手动开关连接3、很好的与各种数据库兼容4、提供了很多第三方插件(分页插件 / 逆向工程)5、能够与Spring很好的整合6、解除sql与程序代码的耦合,SQL写在XML里,从程序代码中彻底分离,且支持编写动态SQL语句7、提供映射标签,支持对象的属性与数据库的字段关系映射25、MyBatis配置一对多?
在resultMap映射中使用collection标签建立一对多的配置关系26、MyBatis配置一对一?
在resultMap映射中使用association标签建立一对一的配置关系27、${ } 和 #{ }的区别?
${ }:sql拼接符号(替换结果不会增加单引号‘’),存在sql注入问题, 名字只能是value#{ }:占位符号(替换结果会增加单引号‘’),可以防止sql注入(预编译),#{名字随意}28、获取上一次自动生成的主键值?
标签selectKey: 查询刚刚自动生成的记录对应的主键值属性keyColumn: 主键对应的字段名
属性keyProperty: 主键对应的属性名
属性order: 查询主键值在插入之前还是之后执行 select last_insert_id()
29、MyBatis如何分页,分页原理?
直接使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页使用分页插件(pageHelper)进行分页基本原理:使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql在sql内直接书写分页(limit)进行物理分页
30、MyBatis工作原理?
MyBatis通过Ser从mybatis-config.xml配置文件来构建S,然后,S的实例直接开启一个S,再通过S实例获得Mapper对象并运行Mapper映射的SQL语句,完成对数据库的CRUD和事务提交,之后关闭S上一篇:2021最新java面试题及答案
下一篇:Java面试题(1)
知识阅读










软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐




-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
5
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14














-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游