1.java基础面试题
发表时间:2022-03-25来源:网络
目录
20210126
1.java有哪些特性
2.什么是JVM?
3.Java跨平台原理
4.什么是GC,为什么要有GC
5.Javase组成
6.JDK与JRE
7.Scanner的nextLine()方法
8.switch使用注意事项
9.简述java基本数据类型及内存空间
10.&与&&区别
11.异常是否抛出,应该站在哪个角度思考?
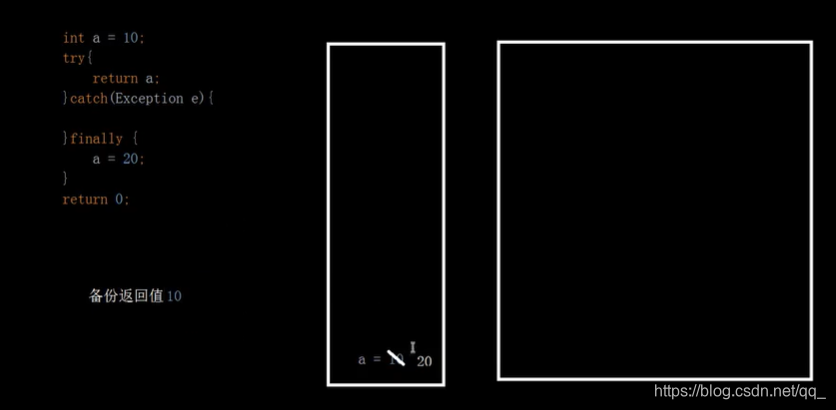
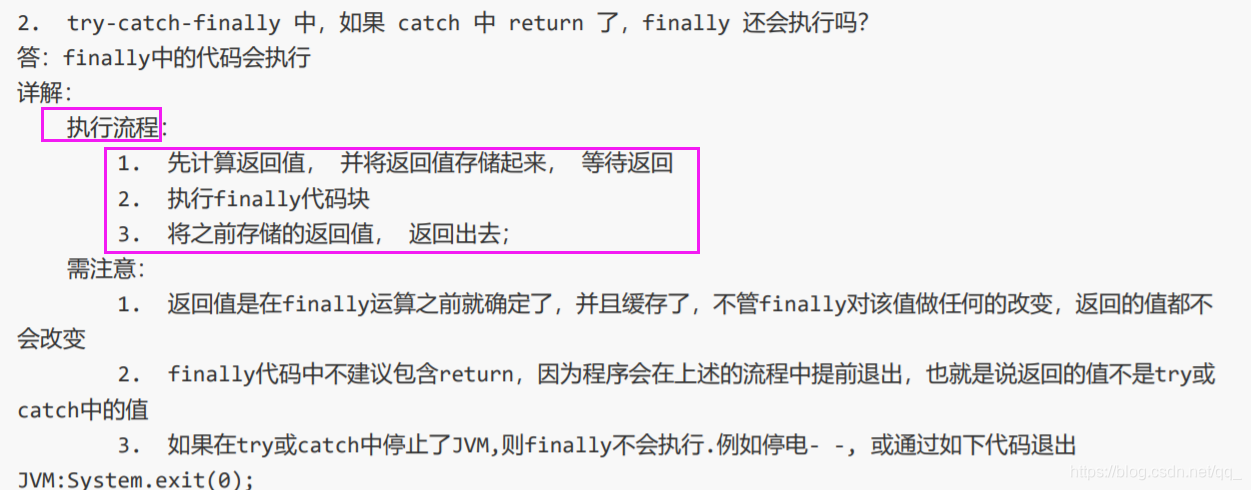
12.finally两个考点:必然执行和return时机
20210128
13.说说你对封装的理解
14.面向过程到面向对象思想层面的转变
15.类与对象关系
16.创建对象内存分析(栈、堆、方法区、PC寄存器、本地方法栈)
16.1.【栈】
16.1.1.Java栈存取数据特点?
16.1.2.栈存储速度快原因?
16.1.3.为什么大部分数据存储到堆内存而不是栈?
16.1.4.栈存储数据的类型
16.2.【堆】
16.2.1.堆存储数据的类型
16.2.2.堆内存与栈内存不同
16.3.【方法区】
16.3.1.方法区可以存放哪些内容?
16.4.【PC寄存器、本地方法栈】
17.static用法
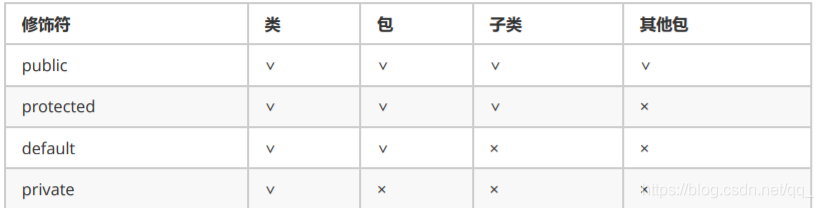
18.权限修饰符使用范围
19.说说单例设计模式
20.抽象类几个问题
21.抽象类和普通类区别
22.面向接口编程优点
23.接口包含哪些?什么时候将类定义成接口?
24.抽象类与接口区别
25.多态的两种体现
20210204
26.数据存储常用结构有哪些?
27.使用栈结构的集合对元素的存取有什么特点?
28.使用队列结构的集合对元素存取有什么特点?
29.使用数组的集合对元素存储的特点?
30.使用单链表的集合对元素存储特点?
31.红黑树结构的集合存储元素特点
32.类集设置的目的、java类集结构图
33.Collection接口常用方法
34.List接口常用方法
35.ArrayList通过无参构造器构造集合初始长度/ArrayList在存储时进行扩容的算法/原理
36.ArrayList与Vector区别(vector实现原理)
37.LinkedList 实现原理及使用
38.Iterator原理和使用
39.Set接口
40.TreeSet与HashSet区别
41.Map、TreeMap、HashMap特点
42.HashMap和Hashtable区别
43.哈希表如何存储元素
44.HashMap源码分析
45.HashMap、Hashtable、ConcurrentHashMap区别
46.散列表散列操作
47.哈希值错乱问题
20210126
1.java有哪些特性
纯面向对象跨平台一种健壮的语言,吸收了 C/C++语言的优点有较高的安全性。(自动回收垃圾,强制类型检查,取消指针)2.什么是JVM?
JVM 可以理解成一个可运行 Java 字节码的虚拟计算机系统.它有一个解释器组件,可以实现 Java 字节码和计算机操作系统之间的通信.对于不同的运行平台,有不同的JVM。JVM 屏蔽了底层运行平台的差别,实现了“一次编译,随处运行”。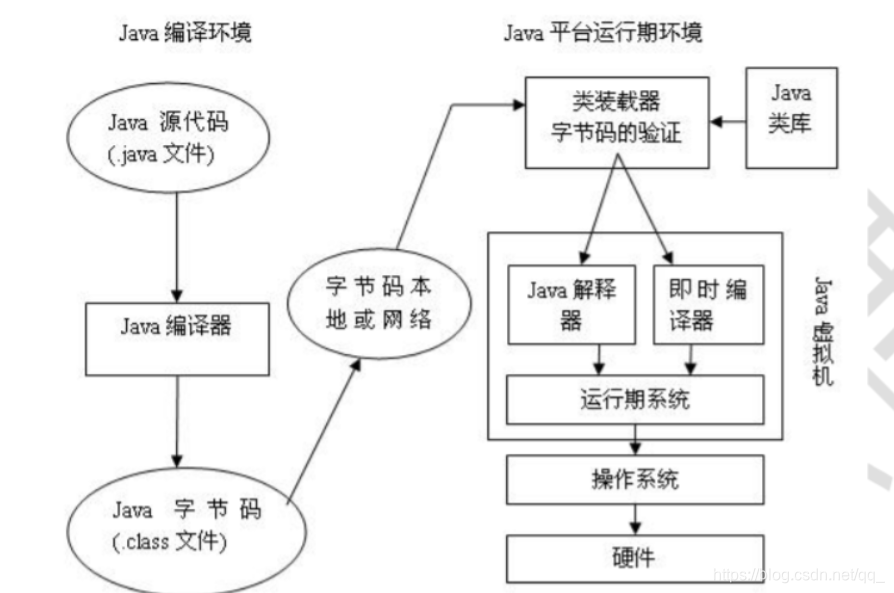
3.Java跨平台原理
java代码经编译器编译成字节码文件,字节码文件被jvm运行,jvm是万能翻译机,将字节码文件翻译给不同操作系统去执行。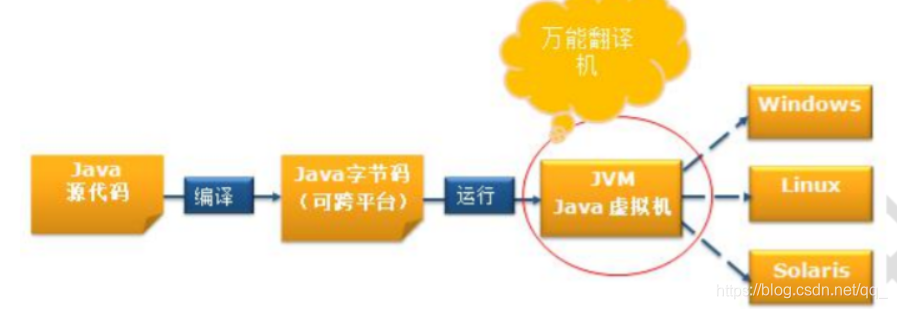
4.什么是GC,为什么要有GC
在 C/C++等语言中,由程序员负责回收无用内存。Java 语言消除了程序员回收无用内存空间的责任: JVM 提供一种系统线程跟踪存储空间的分配情况。并在 JVM 的空闲时,检查并释放那些可以被释放的存储空间。垃圾回收器在 Java 程序运行过程中自动启用,程序员无法精确控制和干预有效的防止内存泄漏和使用内存。5.Javase组成

6.JDK与JRE
JDK(Java Development Kits)-- Java 开发工具集JRE(Java Runtime Environment)Java 运行时环境JDK主要包含:工具程序+API+JRE+JVM Java API (应用程序编程接口)、Java 编译器(javac.exe)、Java 运行时解释器(java.exe)、Java 文档化化工具(javadoc.exe)及其它工具及资源JRE JVMJRE 的三项主要功能: 加载代码:由类加载器(class loader)完成; 校验代码:由字节码校验器(byte code verifier)完成; 执行代码:由运行时解释器(runtime interpreter)完成。7.Scanner的nextLine()方法
Scanner的nextLine()方法为什么有时候接收不到值? 为什么有时候控制台会跳过我的输入直接运行下面的代码?
其实Scanner对象是接收到了值的,否则也不会直接跳过输入过程。它接收到的是一个换行符(\n),是前面的next()、nextInt()等等这样的方法遗留下来的。Next()方法是按照空格来切分的,不会接收\n。想避免这种现象有两种方法: 1.使用nextLine()先接收一次上面遗留的\n,不必保留返回值,再使用String str=scanner.nextLine()保留返回值,接收真正有用的数据;2.在使用nextLine()方法时就不要使用任何其他的next系列方法,需要其他类型都用转型方法+异常处理来解决。nextLine和其他的next方法有冲突,所有输入都使用nextLine,这样不会因为输入产生冲突,还可以接收各种类型数据(parsexxx类型转换)
8.switch使用注意事项
switch有两个参数: ()中必须使用变量,类型必须是String、byte、short、int、char、枚举中的某一种类型,不能是long 类型。case后面跟着的必须是常量;switch仅适用于等值判断场合,发生区间判断的场合仅能使用if-elseif-else方式。switch中的break一般不能省略,省略后会发生case穿透,导致两个case中的代码同时进行,仅适用于确定想让多个case执行相同语句,或多个case的执行代码互相包含时才会选择性省略case,如月份日期的输出、文件更新补丁包的覆盖等等。default语句一般可以省略,适合需要对确定分支之外的所有情况进行判定时使用。前面case定义的变量在后面的case中会发生同名冲突现象,解决方案:将每个case都封装成各自的方法或者单独加上大括号表示分隔。9.简述java基本数据类型及内存空间
描述整数的数据类型主要有:byte/short/int/long,分别占用1个/2个/4个/8个字节大小。描述小数的数据类型主要有:float/double,分别占用4个/8个字节大小。 描述真假的数据类型有:boolean,占用1个字节大小。 描述字符的数据类型有:char,占用2个字节。10.&与&&区别
1.&和&&都可以用作逻辑与的运算符,表示逻辑与(and),全真则真,否则假。
2.&&还具有短路的功能,即如果第一个表达式为 false,则不再计算第二个表达式,例如,对于 if(str!=null &&!str.equals(“”))表达式,当 str 为 null 时,后面的表达式不会执行,所以不会出现 NullPointerException 如果将 &&改为&,则会抛出 NullPointerException 异常。If(x==33&++y>0)y 会增长,If(x==33&&++y>0)不会增长
3.&还可以用作位运算符,当&操作符两边的表达式不是 boolean 类型时,&表示按位与操作,我们通常使用 0x0f 来与一个整数进行&运算,来获取该整数的最低 4 个 bit 位,例如,0x31&0x0f 的结果为 0x01。
11.异常是否抛出,应该站在哪个角度思考?
如果是因为传参导致异常(非方法体问题),则通过throws抛出。12.finally两个考点:必然执行和return时机
public class Demo6 { public static void main(String[] args) { Person p = haha(); System.out.println(p.age); } public static Person haha(){ Person p = new Person(); try{ p.age = 18; return p; }catch(Exception e){ return null; }finally { p.age = 28; } } static class Person{ int age; } } 输出结果28,try中return p返回是备份好的返回值p,但p是引用类型指向内容,而finally中修改了p的内容(堆中),因此备份好的返回值也会改变。备份好的p还没被返回就被修改。如下图: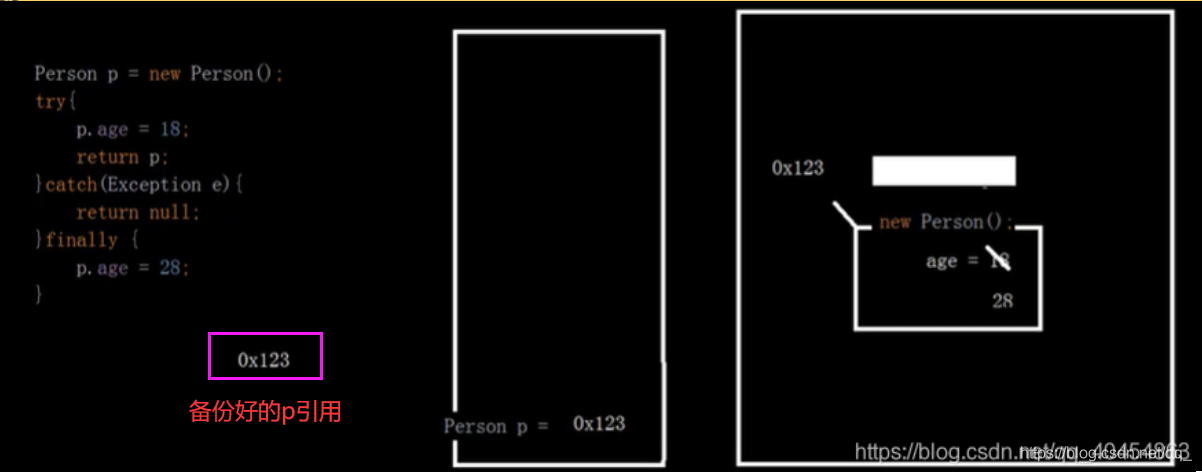
20210128
13.说说你对封装的理解
什么是封装:封装就是把类中的属性给上不同的访问权限,不允许外界随意修改。为什么封装:保护类中的数据不被破坏怎么封装:把类中的属性用不同的访问修饰符修饰,给外界提供可以操作的方法14.面向过程到面向对象思想层面的转变
面向过程关注的是执行的过程,面向对象关注的是具备功能的对象。面向过程到面向对象,是程序员思想上 从执行者到指挥者的转变。15.类与对象关系
类表示一个共性的产物,是一个综合的特征,而对象,是一个个性的产物,是一个个体的特征。类必须通过对象才可以使用,对象的所有操作都在类中定义。类由属性和方法组成: 属性:就相当于人的一个个的特征 ·方法:就相当于人的一个个的行为,例如:说话、吃饭、唱歌、睡觉16.创建对象内存分析(栈、堆、方法区、PC寄存器、本地方法栈)
16.1.【栈】
16.1.1.Java栈存取数据特点?
Java栈的区域很小 , 大概2m左右 , 特点是存取的速度特别快,, 先进后出。16.1.2.栈存储速度快原因?
栈内存, 通过 '栈指针' 来创建空间与释放空间 !指针向下移动, 会创建新的内存, 向上移动, 会释放这些内存 !这种方式速度特别快 , 仅次于PC寄存器 !16.1.3.为什么大部分数据存储到堆内存而不是栈?
栈使用栈指针进行数据存储,必须要明确移动的大小与范围 (需要关注开辟多少空间),明确大小与范围是为了方便指针的移动 , 这是一个对于数据存储的限制, 存储的数据大小是固定的 , 影响了程序 的灵活性 ~ 所以我们把更大部分的数据 存储到了堆内存中16.1.4.栈存储数据的类型
基本数据类型的数据 以及 引用数据类型的引用!16.2.【堆】
16.2.1.堆存储数据的类型
引用类型
16.2.2.堆内存与栈内存不同
堆内存优点在于我们创建对象时 , 不必关注堆内存中需要开辟多少存储空间 , 也不需要关注内存占用 时长 !堆内存中内存的释放是由GC(垃圾回收器)完成的垃圾回收器 回收堆内存的规则:当栈内存中不存在此对象的引用时,则视其为垃圾 , 等待垃圾回收器回收 !16.3.【方法区】
16.3.1.方法区可以存放哪些内容?
存放的是
- 类信息- 静态的变量- 常量- 成员方法方法区中包含了一个特殊的区域 ( 常量池 )(存储的是使用static修饰的成员)
16.4.【PC寄存器、本地方法栈】
PC寄存器存放的内容 PC寄存器保存的是 当前正在执行的 JVM指令的 地址 !在Java程序中, 每个线程启动时, 都会创建一个PC寄存器 !本地方法栈存放的内容 保存本地(native)方法的地址 !17.static用法
static表示“静态”的意思,可以用来修饰成员变量和成员方法(后续还会学习 静态代码块 和 静态内部类)。static的主要作用在于创建独立于具体对象的域变量或者方法简单理解: 被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访 问。 并且不会因为对象的多次创建 而在内存中建立多份数据1. 静态成员 在类加载时加载并初始化。2. 无论一个类存在多少个对象 , 静态的属性, 永远在内存中只有一份( 可以理解为所有对象公用 )3. 在访问时: 静态不能访问非静态 , 非静态可以访问静态 !内存中是【先】有静态内容,【后】有非静态内容,静态方法中不能使用this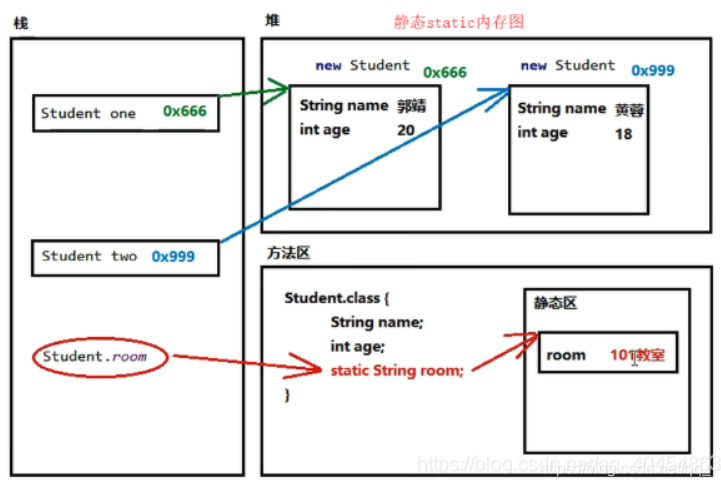
18.权限修饰符使用范围
19.说说单例设计模式
单例设计模式:保证程序在内存中只有一个对象存在(被程序所共享)单例设计模式的两种实现方式: 一、懒汉式:随着类的加载在内存中对象为null,当调用 getInstance 方法时才创建对象(延迟加载)二、饿汉式:随着类的加载直接创建对象(推荐开发中使用)单例设计模式的实现步骤: 1.保证一个类只有一个实例,实现方式:构造方法私有化2.必须要自己创建这个实例,实现方式:在本类中维护一个本类对象(私有,静态) 3.必须向整个程序提供这个实例,实现方式:对外提供公共的访问方式(getInstance方法,静态)懒汉式实现如下: class Single{ private Single(){} private static Single s1 = null; public static Single getInstance(){ if(s1 == null){ s1 = new Single(); } return s1; } } 饿汉式实现如下: class Single2{ private Single2(){} private static Single2 s = new Single2(); public static Single getInstance(){ return s; } void print(){ System.out.println("Hello World!"); } }20.抽象类几个问题
抽象类能被实例化吗? 抽象类本身是不能直接进行实例化操作的,即:不能直接使用关键字new完成。抽象类能否使用final声明? 不能,因为final属修饰的类是不能有子类的 , 而抽象类必须有子类才有意义,所以不能。抽象类能否有构造方法? 能有构造方法,而且子类对象实例化的时候的流程与普通类的继承是一样的,都是要先调用父类中的构造方法(默 认是无参的),之后再调用子类自己的构造方法。21.抽象类和普通类区别
1、抽象类必须用public或protected修饰(如果为private修饰,那么子类则无法继承,也就无法实现其抽象方法)。 默认缺省为 public2、抽象类不可以使用new关键字创建对象, 但是在子类创建对象时, 抽象父类也会被JVM实例化。3、如果一个子类继承抽象类,那么必须实现其所有的抽象方法。如果有未实现的抽象方法,那么子类也必须定义为 abstract类22.面向接口编程优点
这种思想是接口是定义(规范,约束)与实现(名实分离的原则)的分离。优点: 1、 降低程序的耦合性2、 易于程序的扩展3、 有利于程序的维护23.接口包含哪些?什么时候将类定义成接口?
如果一个类中的全部方法都是抽象方法,全部属性都是全局常量,那么此时就可以将这个类定义成一个接口。interface 接口名称{ 全局常量 ; 抽象方法 ; } 因为接口本身都是由全局常量和抽象方法组成 , 所以接口中的成员定义可以简写: 1、全局常量编写时, 可以省略public static final 关键字,例如: public static final String INFO = "内容" ;---> String INFO = "内容" ; 2、抽象方法编写时, 可以省略 public abstract 关键字, 例如: public abstract void print() ;--->void print() ;24.抽象类与接口区别
1、抽象类要被子类继承,接口要被类实现。2、接口只能声明抽象方法,抽象类中可以声明抽象方法,也可以写非抽象方法。3、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。4、抽象类使用继承来使用, 无法多继承。 接口使用实现来使用, 可以多实现5、抽象类中可以包含static方法 ,但是接口中不允许(静态方法不能被子类重写,因此接口中不能声明静态方法)6、接口不能有构造方法,但是抽象类可以有25.多态的两种体现
多态:就是对象的多种表现形式,(多种体现形态)。在类中有子类和父类之分,子类就是父类的一种形态 ,对象多态性就从此而来。多态可以分为两种:设计时多态和运行时多态。设计时多态:即重载,是指Java允许方法名相同而参数不同(返回值可以相同也可以不相同)。
运行时多态:即重写,是指Java运行根据调用该方法的类型决定调用哪个方法。
重载: 一个类中方法的多态性体现重写: 子父类中方法的多态性体现。多态目的:增加代码的灵活度。20210204
26.数据存储常用结构有哪些?
栈、队列、数组、链表和红黑树27.使用栈结构的集合对元素的存取有什么特点?
stack是限定仅在表尾进行插入和删除操作的线性表先进后出栈的入口、出口的都是栈的顶端位置。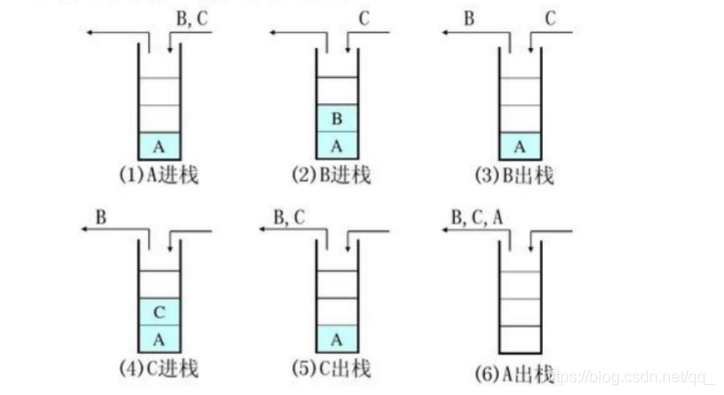
28.使用队列结构的集合对元素存取有什么特点?
queue只允许在表的 一端进行插入,而在另一端进行删除元素的线性表。只允许在表的 一端进行插入,而在另一端进行删除元素的线性表。先进先出队列的入口、出口各占一侧。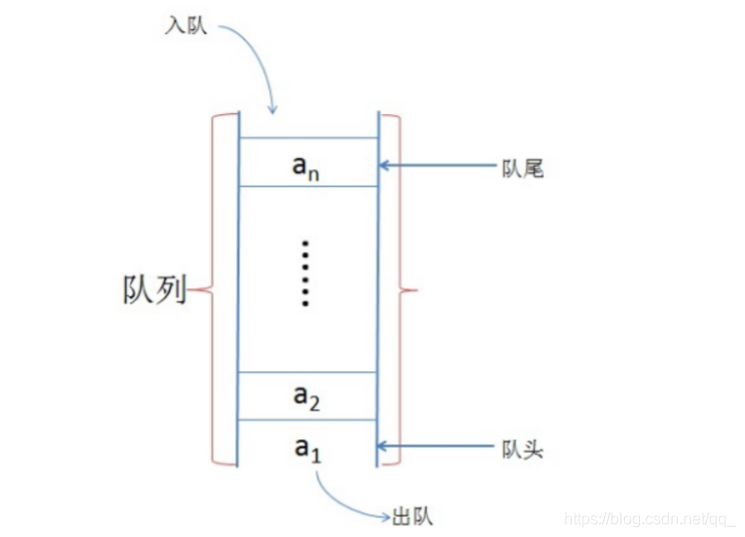
29.使用数组的集合对元素存储的特点?
查找元素快:通过索引,可以快速访问指定位置的元素增删元素慢:增删都需要创建新数组,并将元素复制到新数组。30.使用单链表的集合对元素存储特点?
linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的 指针域。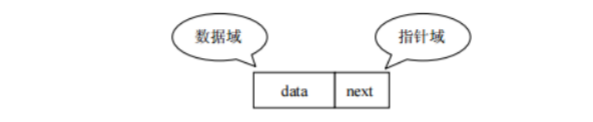

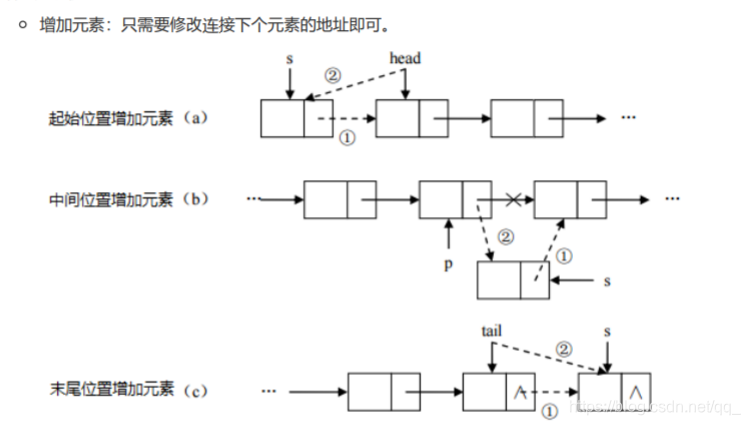
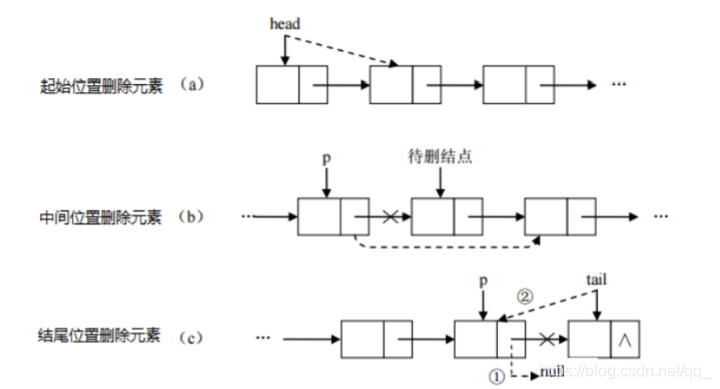
31.红黑树结构的集合存储元素特点
二叉树:binary tree ,是每个结点不超过2的有序树红黑树本身就是一颗二叉查找树红黑树的约束: 1. 节点可以是红色的或者黑色的2. 根节点是黑色的3. 叶子节点(特指空节点)是黑色的4. 每个红色节点的子节点都是黑色的5. 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同红黑树的特点: 二分查找速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍32.类集设置的目的、java类集结构图
普通的对象数组的最大问题在于数组中的元素个数是固定的,不能动态的扩充大小,所以最 早的时候可以通过链表实现一个动态对象数组。但是这样做毕竟太复杂了,所以在 Java 中为了方便用户操作各个数据结构, 所以引入了类集的概念,有时候就可以把类集称为 java 对数据结构的实现。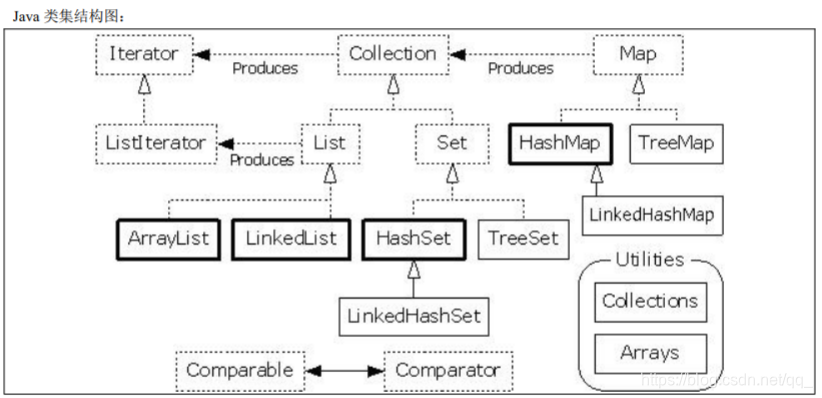
33.Collection接口常用方法
Collection 接口是在整个 Java 类集中保存单值的最大操作父接口,里面每次操作的时候都只能保存一个对象的数据。在开发中不会直接使用 Collection 接口。而使用其操作的子接口:List、Set。为了更加清楚的区分,集合中是否允许有重复元素.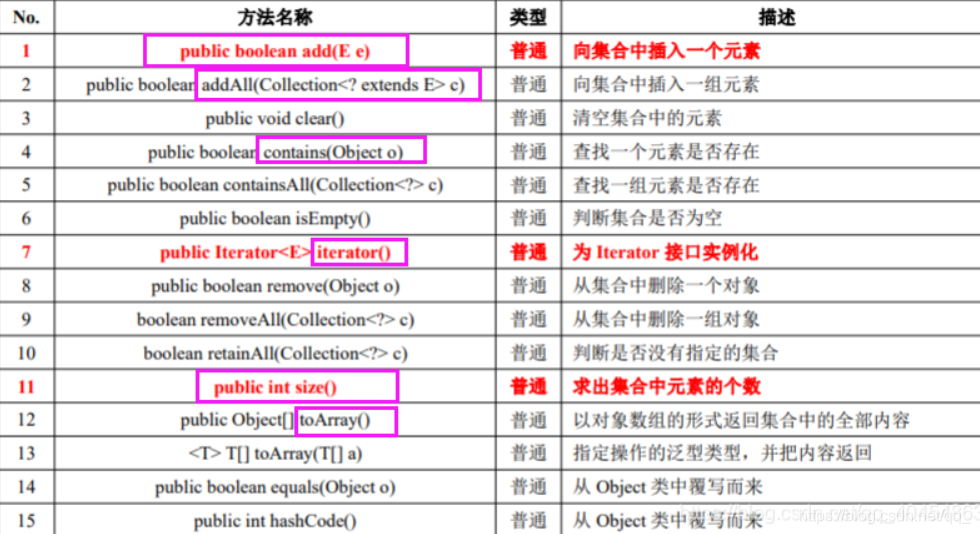
34.List接口常用方法
在 List 接口中有以上 10 个方法是对已有的 Collection 接口进行的扩充。,List 接口拥有比 Collection 接口更多的操作方法。 ArrayList(95%)、Vector(4%)、LinkedList(1%)ArrayList和Vector都是基于数组动态扩容(新老数组复制)在整个集合中 List 是 Collection 的子接口,里面的所有内容都是允许重复的。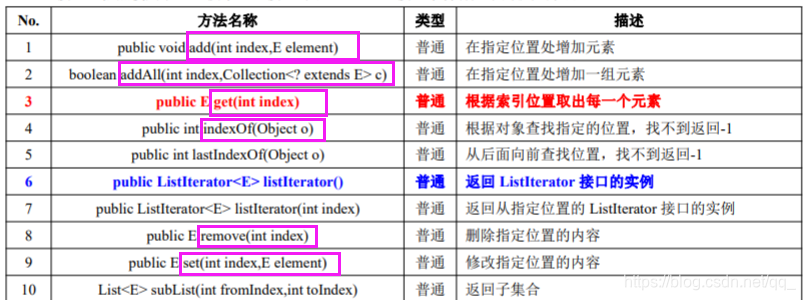
35.ArrayList通过无参构造器构造集合初始长度/ArrayList在存储时进行扩容的算法/原理
ArrayList通过无参构造器构造集合初始长度
下面是api提供的ArrayList构造器初始容量为10,这其实是扩容后的值,最初始值其实是空数组{}.ArrayList()构造一个初始容量为10的空列表。
ArrayList(int initialCapacity)构造具有指定初始容量的空列表。
看下ArrayList构造器源码,点开elementData它是存储数据的数组,点开DEFAULTCAPACITY_EMPTY_ELEMENTDATA这个值是一个默认final的空数组,也就是说通过arraylist无参构造器构造的集合就是一个空数组,初始容量就是0.public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } transient Object[] elementData; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};arraylist扩容算法
创建list就是一个final修饰的空数组,容量0,当通过add方法添加元素时,点开add看下,无论添加成功与否返回的都是true,这是写死的。ArrayList list = new ArrayList(); list.add(100); 里面执行添加的语句是add(e, elementData, size);传递三个参数,一个是待添加的元素e,一个是存数据的数组elementData,最后一个是有效数组实际长度size. public boolean add(E e) { modCount++; add(e, elementData, size); return true; } 点开add(e, elementData, size)看看是如何进行添加元素?如果数组有效长度s等于数组长度length,则数组已满,调用grow()进行扩容并返回扩容后数组,否则直接将元素存入elementData中。 private void add(E e, Object[] elementData, int s) { if (s == elementData.length) elementData = grow(); elementData[s] = e; size = s + 1; } grow()如何进行扩容?将目前数组长度(满长)加1作为数组最小容量传入到grow(int minCapacity)方法中,该方法中通过旧数组elementData和计算的新长度copyof出新数组给到elementData。新的长度通过newCapacity(minCapacity)方法计算出来,传参传的是最小需要的数组长度(原数组+1), private Object[] grow() { return grow(size + 1); } private Object[] grow(int minCapacity) { return elementData = Arrays.copyOf(elementData,newCapacity(minCapacity)); } newCapacity(minCapacity)是如何计算新数组长度?先获取旧长度oldCapacity(数组存满时总长度),新长度newCapacity是旧长度+旧长度右移1位(即二进制右移一位即旧长度除以2)即旧长度的1.5倍。下面做一个判断,若是新长度小于等于旧长度,说明新长度不够(比如未添加元素前初始长度是0,1.5倍还0;再比如添加一组数据,长度不可控时也是会进入判读)。 进一步判断若数组elementData是默认初始空数组{},则返回默认长度DEFAULT_CAPACITY(即10)与最小需要长度minCapacity(旧长度+1)两者最大值作为新长度,API中说的初始容量10就是新建的list第一次添加元素后容量。另外当minCapacity长度超出int范围就会溢出,内存中二进制超出位数,然后由于符号的改变导致minCapacity变成负数,所以这里抛出一个内存溢出异常。如果elementData不是 DEFAULTCAPACITY_EMPTY_ELEMENTDATA即默认空数组{}即不是第一次添加元素又或者没有抛异常,则返回最小需要长度minCapacity即需要多少就多少刚好够存储.若扩容以后新长度newCapacity够用,且新长度比允许的最大长度MAX_ARRAY_SIZE(即int类型最大值-8)小则返回新长度,若新长度比允许最大长度还大,则返回hugeCapacity(minCapacity)private int newCapacity(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity threshold) resize(); afterNodeInsertion(evict); return null; }45.HashMap、Hashtable、ConcurrentHashMap区别
HashMap线程不安全、但效率高(多人同时做同一件事(存取删),若存在共享数据则出现线程安全问题)Hashtable线程安全、效率低。(多人排队做一件事情)。ConcurrentHashMap采用分段锁机制,保证线程安全,效率较高。即锁住的范围只是一个桶,其他人可以对其它桶操作。Hashtable锁住的是整个集合。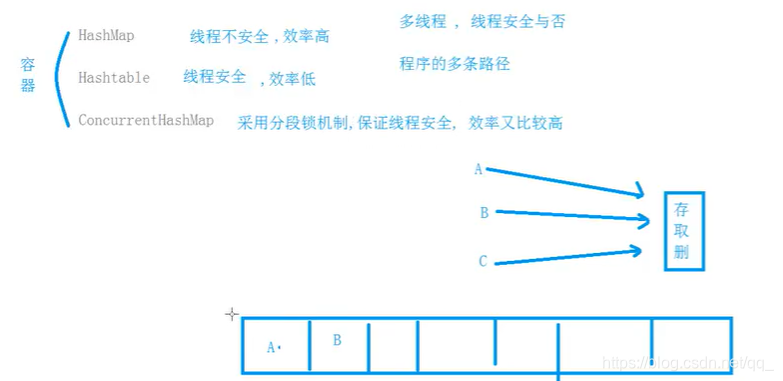
46.散列表散列操作
影响HashMap性能的参数:初始容量、负载(散列)因子。若初始容量给的小,但存储的数据很多,哈希表就会频繁的散列,即重建内部数据结构即重新建立2倍大小哈希表,将原数据再一一存进去,这样导致最后存储数据次数是原来多倍,造成性能浪费。加载因子若给的小,则占用大量内存空间但效率高,若过大则越节省空间但查询效率过低。47.哈希值错乱问题
当一个对象作为哈希表的键存储时,这个对象就不要进行修改,不然重新计算的哈希值与原来哈希值会不一样,就找不到原数据,造成内存泄漏。只要是以哈希表存储元素,被计算哈希值的字段内容就不要修改,若一定要修改,这个字段就不要放在键的位置,当然这是对map来说,若是对set来说只能存单列,是一定不能修改的。比如当一个对象被存进 HashSet 集合后,就不能修改这个对象中的那些参与计算的哈希值的字段了,否则,对象被修改后的哈 希值与最初存储进 HashSet 集合中时的哈希值就不同了,在这种情况下,即使在 contains 方法使用该对象的当前引用作为 的参数去 HashSet 集合中检索对象,也将返回找不到对象的结果,这也会导致无法从 HashSet 集合中删除当前对象,从而 造成内存泄露。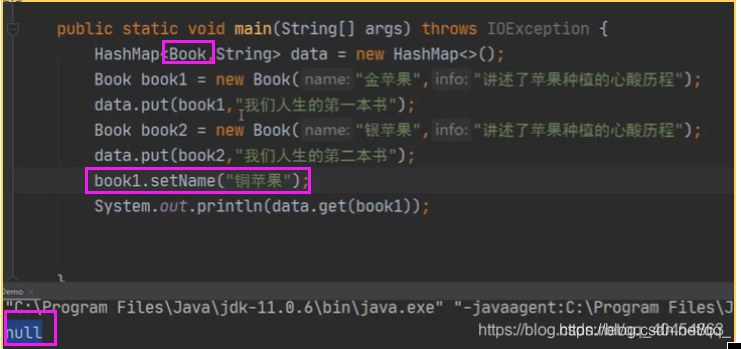
上一篇:Java中的经典面试题
下一篇:Java 工厂模式简述
知识阅读










软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐




-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
5
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14














-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游